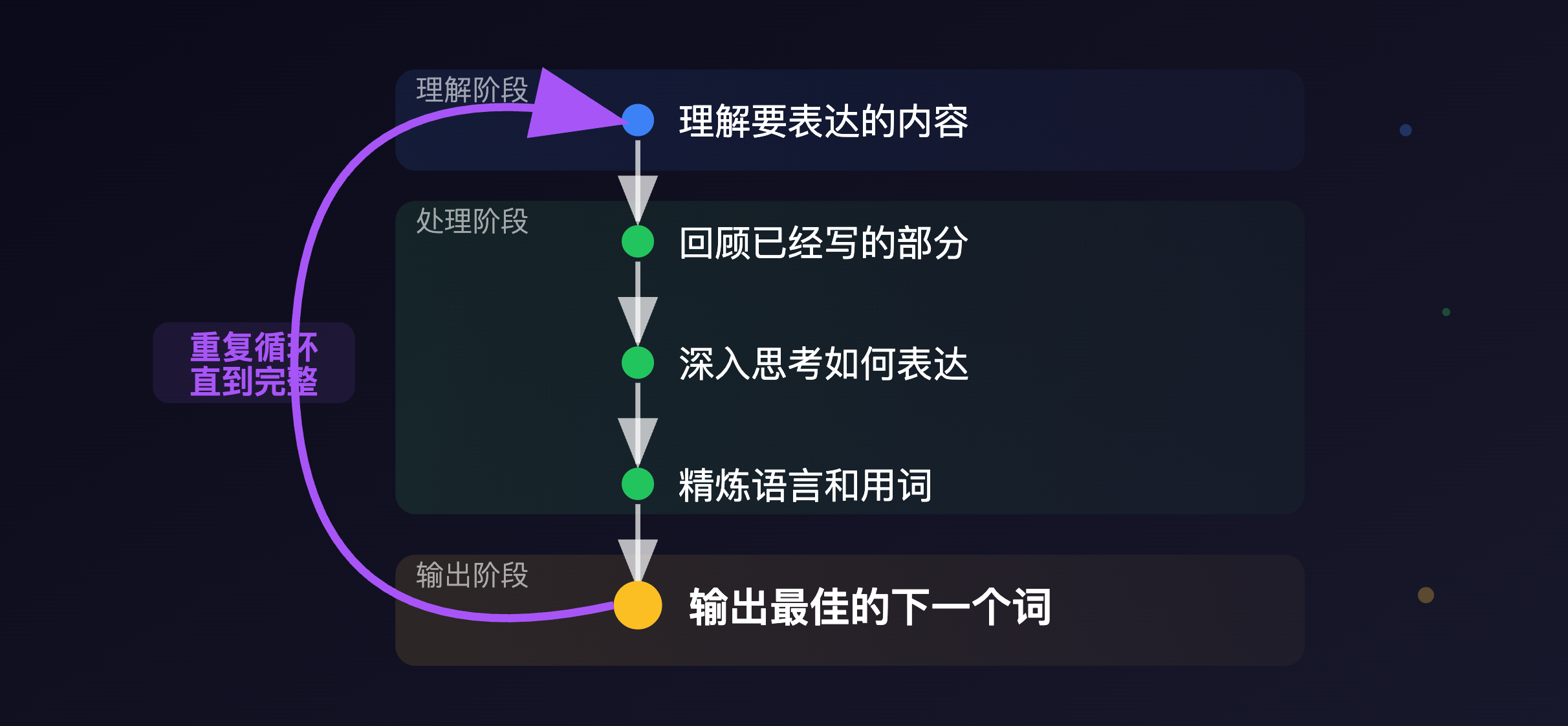
初始面对问题时,我们难以把握所有细节和边界。问题域与求解空间构成一座迷宫。
当委托 Agent 去解决时,迷宫越大,Agent 面临的方向和不确定因素越多,路径越发散,越容易迷失。对于系统性任务,若无章法和收敛判断,Agent 在前进不远的地方,可能就会陷入困局。
这正是 SKILL 存在的意义:为迷宫划定边界,并为每一步提供导航,并让 Agent 知道自己何时需要停下来。。
初始面对问题时,我们难以把握所有细节和边界。问题域与求解空间构成一座迷宫。
当委托 Agent 去解决时,迷宫越大,Agent 面临的方向和不确定因素越多,路径越发散,越容易迷失。对于系统性任务,若无章法和收敛判断,Agent 在前进不远的地方,可能就会陷入困局。
这正是 SKILL 存在的意义:为迷宫划定边界,并为每一步提供导航,并让 Agent 知道自己何时需要停下来。。
LLM 具备强大的分析能力、推理能力、生成能力,但它仍然无法记得上个月的今天发生了什么,哪怕你曾经在上个月告诉过它。
究其原因,是因为 LLM 基于静态语料库训练,你的个人经历并不在其中。它只具备短期记忆,这种记忆依靠一次对话的上下文维持(历史信息会被携带到下一次对话),当你换个对话窗口,它就忘记了。
当然,现在的诸多协议已经能够为 LLM 提供很多”外挂”,比如 MCP 协议、A2A 协议,它们在不断扩展 LLM 的认知边界,让 LLM 能够跳出其固有的知识范围。但是,RAG 仍然是一个重要方向,为 LLM 提供长期记忆、让它能够将神经元触达到你的个人数据。
AI模型已然从文字走向多模态,能力边界不断拓展。从斯坦福小镇到 ChatDev,再到 AutoGen 和 LangGraph,多 Agent 协作模式也在不断发展。
个体越聪明,协作越复杂,群体智慧越强大——人类如此,AI亦然。
当个体 LLM 成熟到一定程度,协作复杂度达到新的临界点,A2A(Agent to Agent)协议的出现,为智能体互联提供标准化规范。
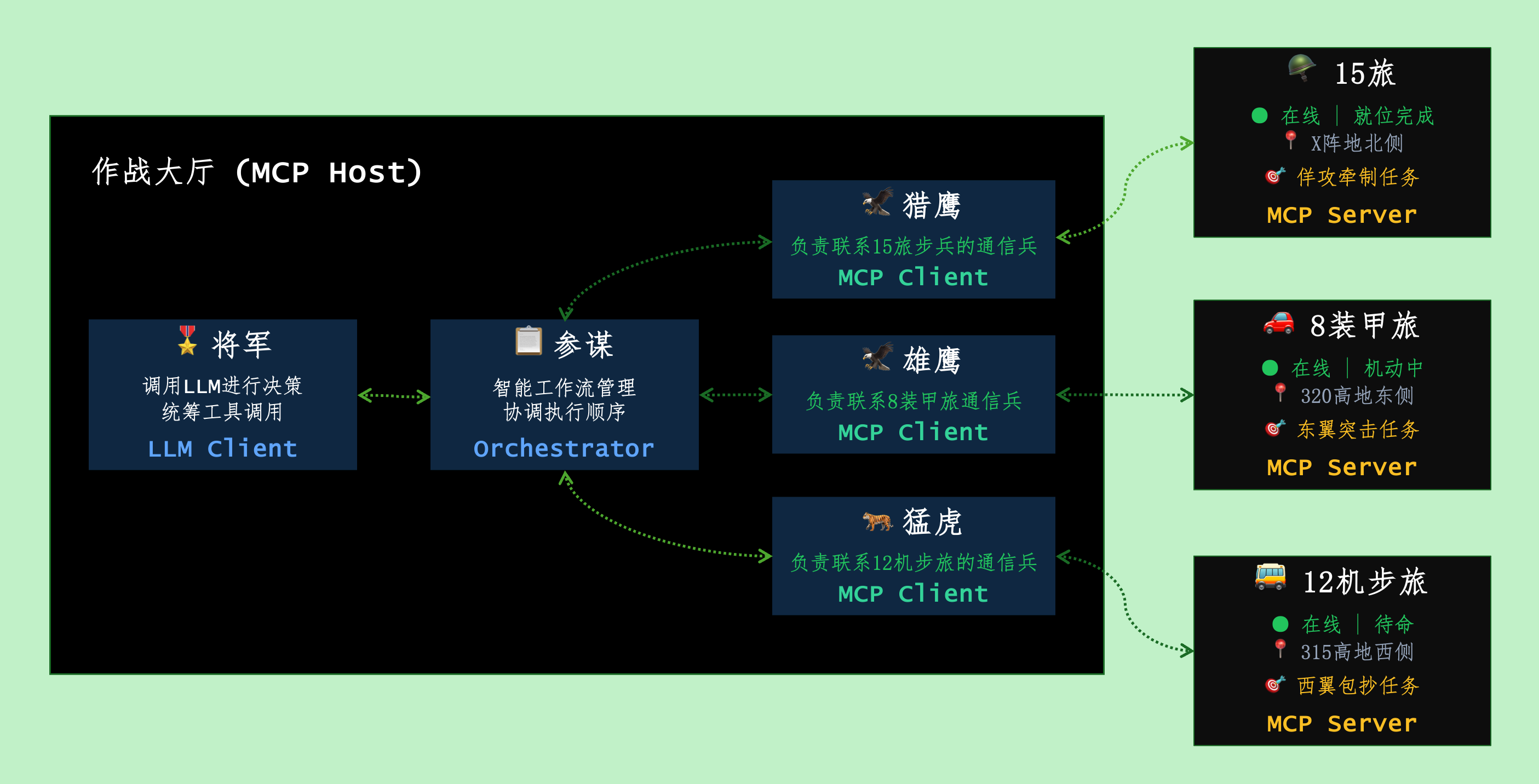
Host 就像是一个作战大厅,大厅里主要有三种角色:

词语的语义受其上下文影响。例如,”model”一词在”machine learning model”与”fashion model”中表达完全不同的概念。
这种影响因素的计算和捕捉,正是 transformer 模型中 self-attention 机制的核心功能之一。

词语的位置决定其语义功能,这是 seq2seq 模型必须解决的核心问题。比如,I saw a saw,两个 saw 在不同位置含义完全不同。
Transformer 模型并行处理所有输入词汇,失去了序列的内在顺序。位置编码通过将位置信息注入输入表示来解决这一问题。理想的位置编码应具备两个数学特性:位置的唯一性(不同位置有不同编码)和相对位置的可学习性(位置间的关系可被模型捕捉)。

神经网络的学习过程,亦如我们设置了一系列的函数,通过学习,让参数更加合理化,从而拟合从输入到输出的映射关系。
下面,通过 ResNet 结构,来理解神经网络的学习过程。

卷积可以用于特征提取,归一化可以用于提高模型的泛化能力,池化可以用于减少特征的维度。