
随着 OpenAI 的兴起,LLM 仿佛是在一夜之间,忽然闯入到普通人的生活。我们该如何和它对话,如何把它带入到这个现实世界,类似 LangChain 这样的框架,或许给我们提供了一整套的解决方案。
LangChain 初次见面,这里,先去认识它的基本概念。
LangChain
LangChain 是一个框架,用于开发由 语言模型(LM) 驱动的应用程序。
理解数据和环境感知是 LangChain 的两个核心原则。
LangChain 包含以下几个模块:
Models:LangChain 提供了和主流 Model 交互的标准接口。
1
2
3
4
5from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
text = "What would be a good company name for a company that makes colorful socks?"
print(llm(text))Prompts:Prompt 提供了对用户输入的封装,并提供了输入的环境,让模型在处理时能够更加聚焦问题本身。
1
2
3
4
5
6
7
8from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
print(prompt.format(product="colorful socks"))
llm(prompt)以上,Model 和 Prompt 就构成了最简单的 LLM 应用。
Memory:LLM 和 Chains 是无状态的,但是在某些应用下,我们又需要一个上下文,这就是 Memory 出现的意义。
1
2
3
4
5
6
7from langchain import OpenAI, ConversationChain
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="Hi there!")
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")Indexes:在基于私域数据使用语言模型的时候,向量索引将是一个很强大的工具。向量索引提供了文本相关性的比较策略,基于该策略,问答可以是私域数据相关的。
Chains:一系列顺序地调用,就是一个链。在链上的组件可以是一个 LLM 或者其他工具。
1
2
3
4
5
6
7
8
9
10
11from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMChain
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
chain.run("colorful socks")通过 Chain 我们可以完成一些更加复杂的工作。上述就是简单的示例:将 prompt 和模型 llm 链接在一起。事实上,我们也可以将不同的信息源或者 LLM 链接起来构成一个更加复杂、明确的调用链。
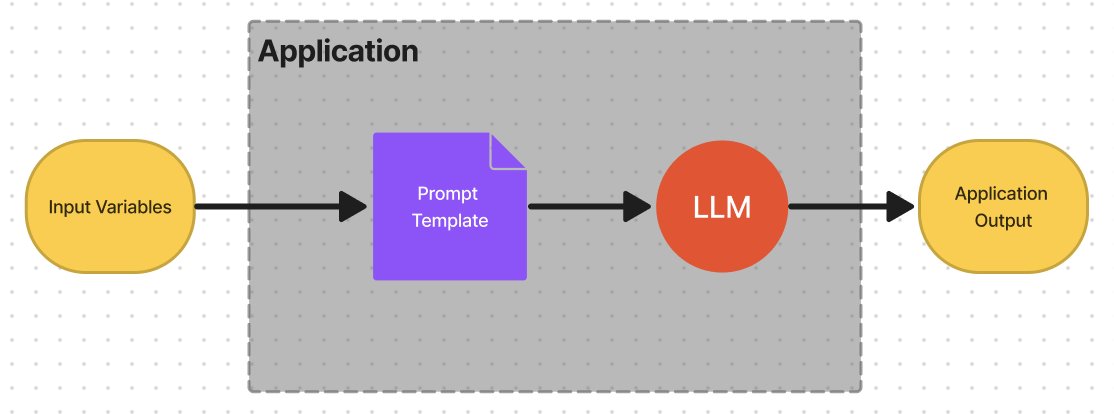
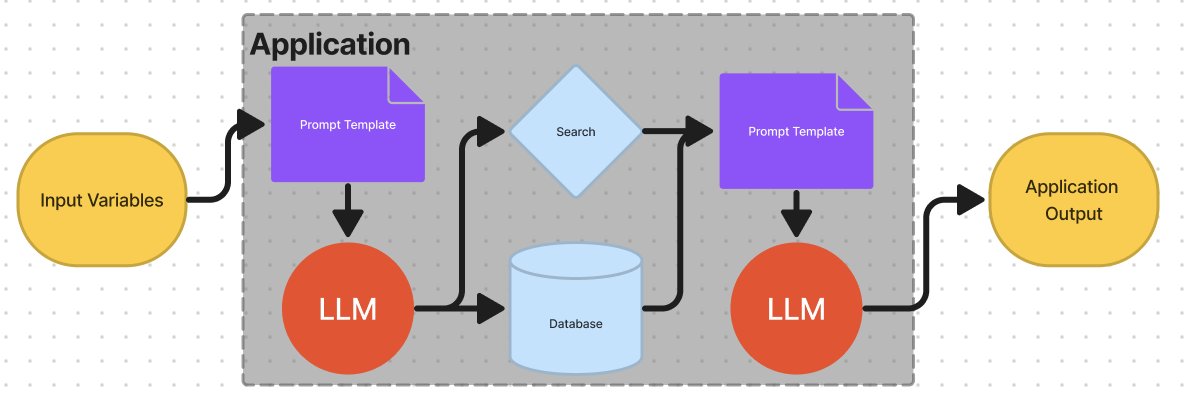
- Agents:Agents 可以处理更加复杂的工作。在 Agent 中封装更加复杂的逻辑,可以让 Agent 去决定调用哪些 LLM 、工具甚至别的 Agent。
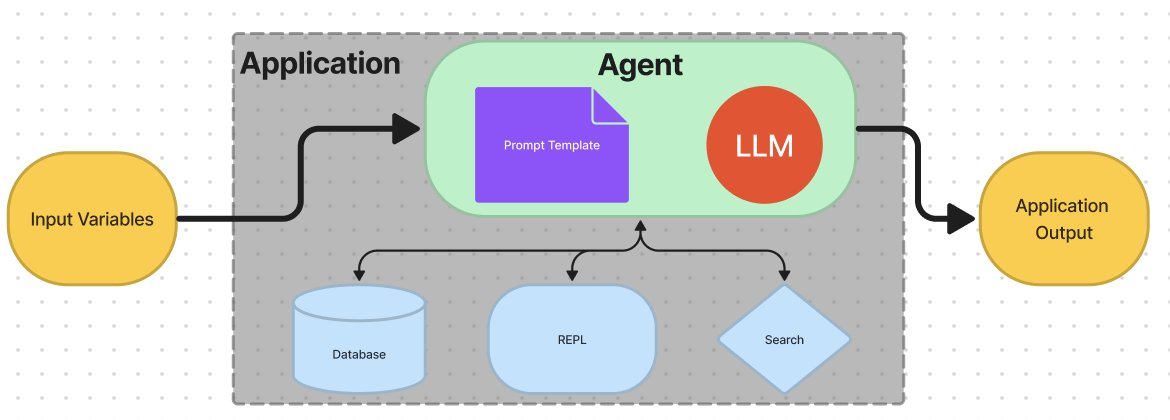
Models
LLMs
LLMs 是 LangChain 的核心组件。LangChain 并不是 LLMs 的提供者(LLM provider 包括:OpenAI、Cohere、Hugging Face等),但是提供了和各种 LLMs 交互的标准接口。
LLM 类就是用来和各种 LLMs 交互的。
1 | from langchain.llms import OpenAI |
Chat Models
Chat model 的底层还是 LLM,不同的是,它的 API 所暴露出的接口并不是 “文本输入、文本输出” 这种形式,而是使用 “chat message” 作为输入和输出。
1 | from langchain.chat_models import ChatOpenAI |
如上,可以看出,这种形式可以允许多个输入和输出,可以构建一个上下文。
事实上,也可以通过 MessagePromptTemplate 或者 ChatPromptTemplate 创建 Prompt 模板。
1 | template="You are a helpful assistant that translates {input_language} to {output_language}." |
进一步的,也可以使用 LLMChain 来简化上面的问答
1 | chain = LLMChain(llm=chat, prompt=chat_prompt) |
Text Embedding Models
Embedding 提供了和具体的 embeddings(OpenAI、Cohere、Hugging Face 等都是具体 embeddings 的提供者) 交互的标准接口。
Embeddings 将文本转化为向量,即文本作为输入,浮点数组作为输出。这样我们就可以在向量空间中考虑文本,利用向量空间的特性,我们可以找到最相近的两个文本。
LangChain 中,一个 Embedding 对象有两个公开的方法:embed_documents 和 embed_query。这两个方法最大的区别就是 一个是针对多个文档,一个针对单个文档。
以下,我们以 OpenAI 为例
1 | from langchain.embeddings import OpenAIEmbeddings |
Prompts
Prompt 代表着 model 的输入。LangChain 提供了几个类可以快速构建出一个 Prompt,比如 PromptTemplate。
LLM Prompt Templates
一个 Prompt 通产包括:
- 指令
- 少量示例,以帮助模型产生更好的答案
- 问题
1 | from langchain import PromptTemplate |
如上,可以在 Prompt 模板中设置若干个输入变量。
为了能够让语言模型给出更好的答案,我们可以给模型提供更多的示例。这时候,就可以使用 FewShotPromptTemplate,它实际上也是使用了一个 PromptTemplate 和一组示例。
1 | from langchain import PromptTemplate, FewShotPromptTemplate |
Chat Prompt Templetes
Chat Models 使用一组 chat message 作为输入。相应的,可以使用 MessagePromptTemplate 作为一个 chat message 的 prompt 模板,而 ChatPromptTemplate 可以包含有多个 MessagePromptTemplate.
1 | from langchain.prompts import ( |
Example Seletors
我们也可以创建一个示例库,在需要的时候从中选择其中若干个到 Prompt 中。ExampleSelector 就是负责做这类事情的。
基本的 ExampleSelector 信息定义如下:
1 | class BaseExampleSelector(ABC): |
如上,我们需要实现 select_examples 方法。接下来,让我们实现一个:
1 | from langchain.prompts.example_selector.base import BaseExampleSelector |
Indexes
通过 Indexes,可以构建和 LLMs 更好地与 documents 进行交互。
indexes 最常用在检索中。
可以通过 BaseRetriever 来了解 Retriever 的定义:
1 | from abc import ABC, abstractmethod |
默认情况下,LangChain 使用 Chroma 作为向量存储索引,我们也使用它来完成 indexes 的应用实例。
1 | pip install chromadb |
关于 documents 的问答,通常包括四个步骤:
- 创建索引
- 为该索引创建一个检索器 Retriever
- 创建问答链
- 问问题
1 | from langchain.chains import RetrievalQA |
接下来创建索引
1 | from langchain.indexes import VectorstoreIndexCreator |
index 已经被创建,现在我们就可以使用它来提问了。
1 | query = "What did the president say about Ketanji Brown Jackson" |
VectorstoreIndexCreator 做了什么呢?
当 documents 被载入后:
- 把 documents 分割成块,即若干个 document;
- 为每个 document 创建一个 embeddings;
- 在 vectorstore 中存储 documents 和 embeddings。
1 | from langchain.text_splitter import CharacterTextSplitter |
VectorstoreIndexCreator 实际上就是上述逻辑的封装。
1 | index_creator = VectorstoreIndexCreator( |
Memory
默认情况,Chains 和 Agents 都是无状态的。在有些应用中,上下文是十分重要的,比如聊天机器人。
LangChain 提供了两种形式的 Memory 组件。首先,LangChain 提供了一些帮助工具以管理、操作先前的 chat messages;其次,LangChain 提供了简单的方式将这些工具集成到 Chains 中。
1 | from langchain.memory import ChatMessageHistory |
1 | from langchain.llms import OpenAI |
Chains
单独使用 LLM 完成一个简单的示例是没有问题的,但通常,更复杂的环境下,我们需要链式的 LLMs。
Chains 允许我们将多个组件组合在一起,创建一个单一的、连贯的应用。比如,我们可以创建一个使用 PromptTemplate 对用户输入进行格式化,将格式化后的数据传入到 LLM,最后接受格式化输出的链。
LangChain 提供了 Chains 的标准接口,以及一些通用的功能。LLMChain 就是一个简单的 Chain 的实现。
1 | from langchain.prompts import PromptTemplate |
也可以通过将多个链组合在一起,构建一个更加复杂的链。
1 | from langchain.chains import SimpleSequentialChain |
Agents
某些应用中,不仅仅使用一个预定义的 Chain 来链接 LLMs 或者其他工具进行工作,具体使用哪个 Chain 可能取决于用户的输入。这正是 Agents 出现的价值。
它通常会包含以下几个部分:
Tools:agent 和外部世界进行交互的工具,比如 Google Search、数据库查询或者其他 Chains。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# Load the tool configs that are needed.
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
# Construct the agent. We will use the default agent type here.
# See documentation for a full list of options.
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26> Entering new AgentExecutor chain...
I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.
Action: Search
Action Input: "Leo DiCaprio girlfriend"
Observation: Camila Morrone
Thought: I now need to calculate her age raised to the 0.43 power
Action: Calculator
Action Input: 22^0.43
> Entering new LLMMathChain chain...
22^0.43
\```python
import math
print(math.pow(22, 0.43))
\```
Answer: 3.777824273683966
> Finished chain.
Observation: Answer: 3.777824273683966
Thought: I now know the final answer
Final Answer: Camila Morrone's age raised to the 0.43 power is 3.777824273683966.
> Finished chain.LLM:为 agent 赋能的语言模型。
Agents:决定该采取什么动作。
https://twitter.com/hwchase17/status/1595246702885507072
ChatGPT|LangChain Agent原理介绍
ChatGPT Prompt工程:设计、实践与思考
LangChain:Model as a Service粘合剂,被ChatGPT插件干掉了吗?
LangChain