本文是一篇翻译,原文地址
当前大多数工作流,主要可以分为两种:基于反思的和基于规划的。
基于反思的工作流
这种模式的工作流允许 agent 从经验中学习,以提升适应性和弹性。它强调从过往经验中学习。
通过分析过往的动作和输出,以优化(refine)未来的行为。
Basic Reflection: Reflecting and learning from the steps.
Reflexion: Enhancing the next steps of the Agent through reinforcement learning.
Tree search: TOT + reinforcement learning-based reflection.
Self-Discover: Reasoning within the task.
基于规划的工作流
规划可以被视为一种基于目标的推理,它通过构建一个目标来指导 agent 的行为。
它将复杂的任务分解成可管理的子任务,并对它们进行逻辑排序,以实现目标。
Plan & Solve: Plan → Task list → RePlan.
LLM compiler: Plan → Action in parallel → Joint execution.
REWOO: Plan (including dependencies) → Action (depends on the previous step).
Storm: Search for outline → Search each topic in the outline → Summarize into a long text.
我们将这个工作流视为一个协调程序。每个节点可以代表一个 LLM 任务、一个可执行函数、一个 RAG 任务等。我们设计这样一个工作流作为一个灵活的编排器,以处理各种复杂的任务。
在本文中,我们将两种特定的工作流设计模式:ReAct 模式和 Plan-Slove 模式。
ReAct 模式
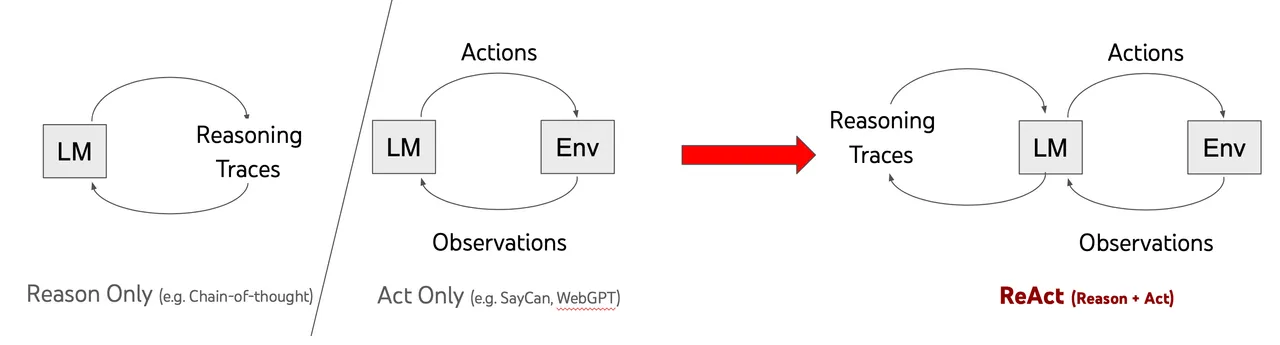
ReAct 非常直观的反映了一个人类智能的核心方面:通过语言推理指导行动。
在每一步,中间都会有 观察 和 自我反思:我做了什么?我完成了目标了吗?这使得 agent 能够保留短期记忆。
设想,你正在让某人帮你在你的桌子上找一支笔,然后你给出了分步说明:
- 首先检查笔架;
- 然后,看看抽屉;
- 最后,检查下显示器后面。
如果没有 ReAct,无论笔在哪里找到,这个人将遵循所有步骤,检查每个位置(Action)。
当使用 ReAct 时,这个过程就像是这样:
- Action 1:首先,检查笔架;
- Observation 1:没有找到笔,因此,请进行下一步;
- Action 2:然后,看看抽屉;
- Observation 2:观察抽屉中是否有笔;
- Action 3:从抽屉中找到笔。
ReAct 的实现
在回顾了几个开源代码之后,让我们专注一个最简单的示例进行分析。你会注意到,从本质上讲,所有 Agent 的设计模式都是围绕着人类思维和管理策略转为为结构化提示展开all Agent design patterns revolve around translating human thinking and management strategies into structured prompts.
代码逻辑如下图所示: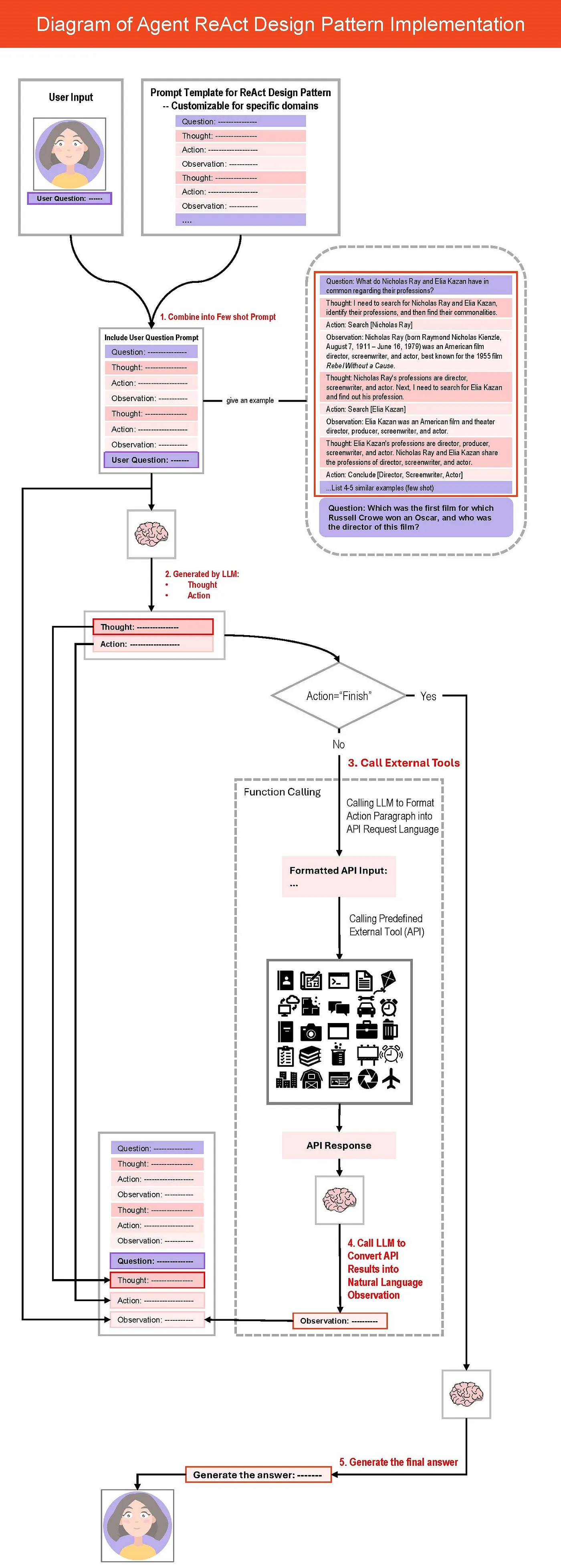
1. 构建提示词
首先,我们使用 ReAct 模板(问题->思考->行动->观察),作为 Few Shot 的例子。同时,抛出问题。
2. 调用 LLM 生成 思考+行动
接着,将 Few Shot 提示词投递给 LLM。LLM 将生成思考,行动以及观察的响应。由于 Action 并未被完整定义,我们通过 Stop.Observation 来终止。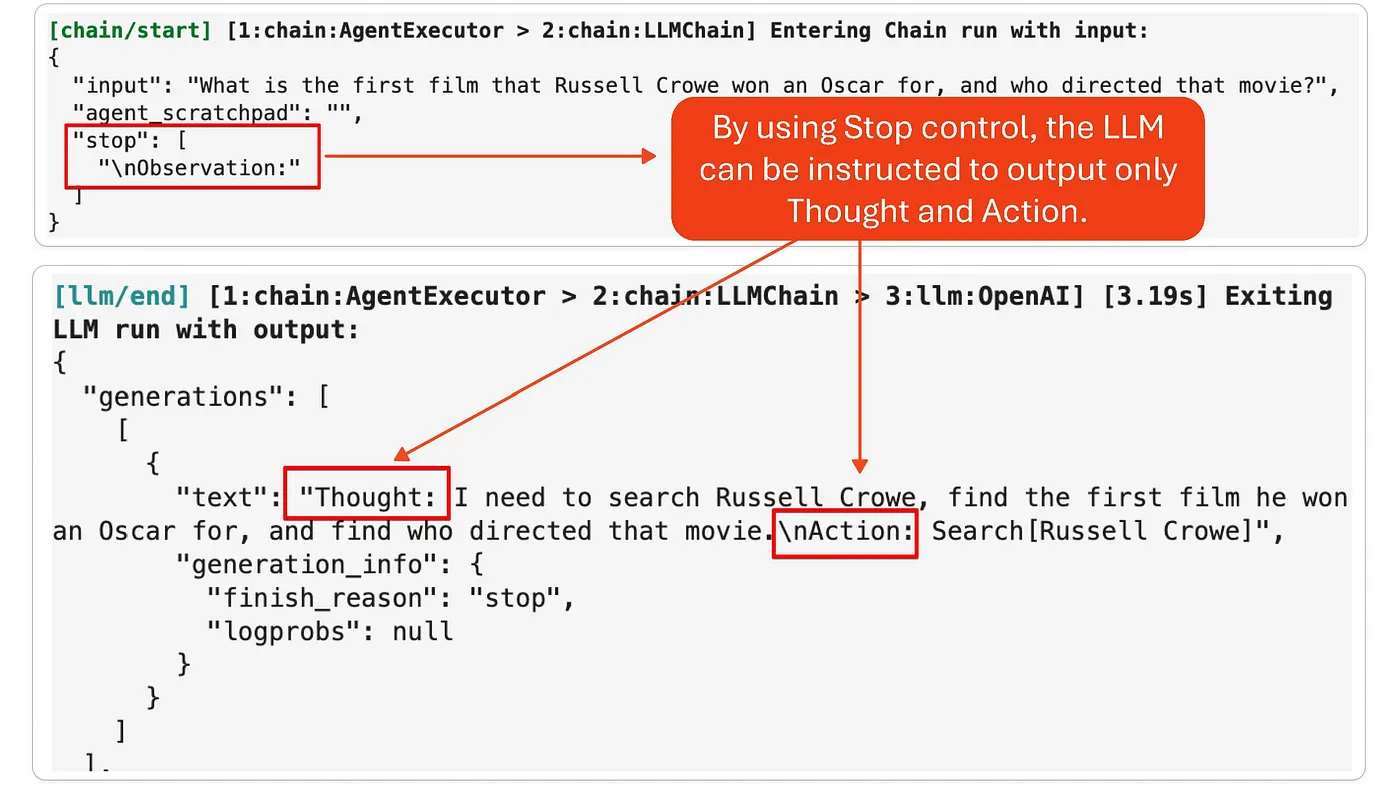
3. 调用外部工具
获取到 Action 之后,我们调用外部工具了。首先,检查结果是否完成,如果不是,模型会使用函数调用功能将 Action 转换成 API 兼容的格式。
4. 生成观察
API 接口返回结果后,转换成自然语言输出,并生成 Observation。然后,观察结果、之前生成的想法以 Action 被输入会模型,重复 2 和 3,直至完成任务。
5. 最终输出
将最终观察的结果转换成自然语言输出给用户。
由此,我们可以看出,在特定场景下实现Agent需要定制两个关键组件:
- 提示模板中的几个例子
- 函数调用外部工具的定义
模板是理解代理设计的好方法。一旦掌握了这种方法,它就可以类似地应用于其他设计模式。
Plan-Solve 模式
谋定而后动。
如果说,ReAct 更适合那种 “在桌子上找笔” 的场景,那么 Plan-Solve 更适合“泡一杯纯白咖啡”。你需要为此制定一个计划,同时,计划在执行过程中可能会发生变化,You need to plan, and the plan might change during the process. 比如,如果你打开冰箱未发现牛奶,你需要把“购买牛奶”加入到计划中。
关于提示词的模板,paper 的名字已经很清楚了。 Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models。简而言之,它是为了提升零样本的推理能力。下图汇总了一些作者代码中的提示词模板。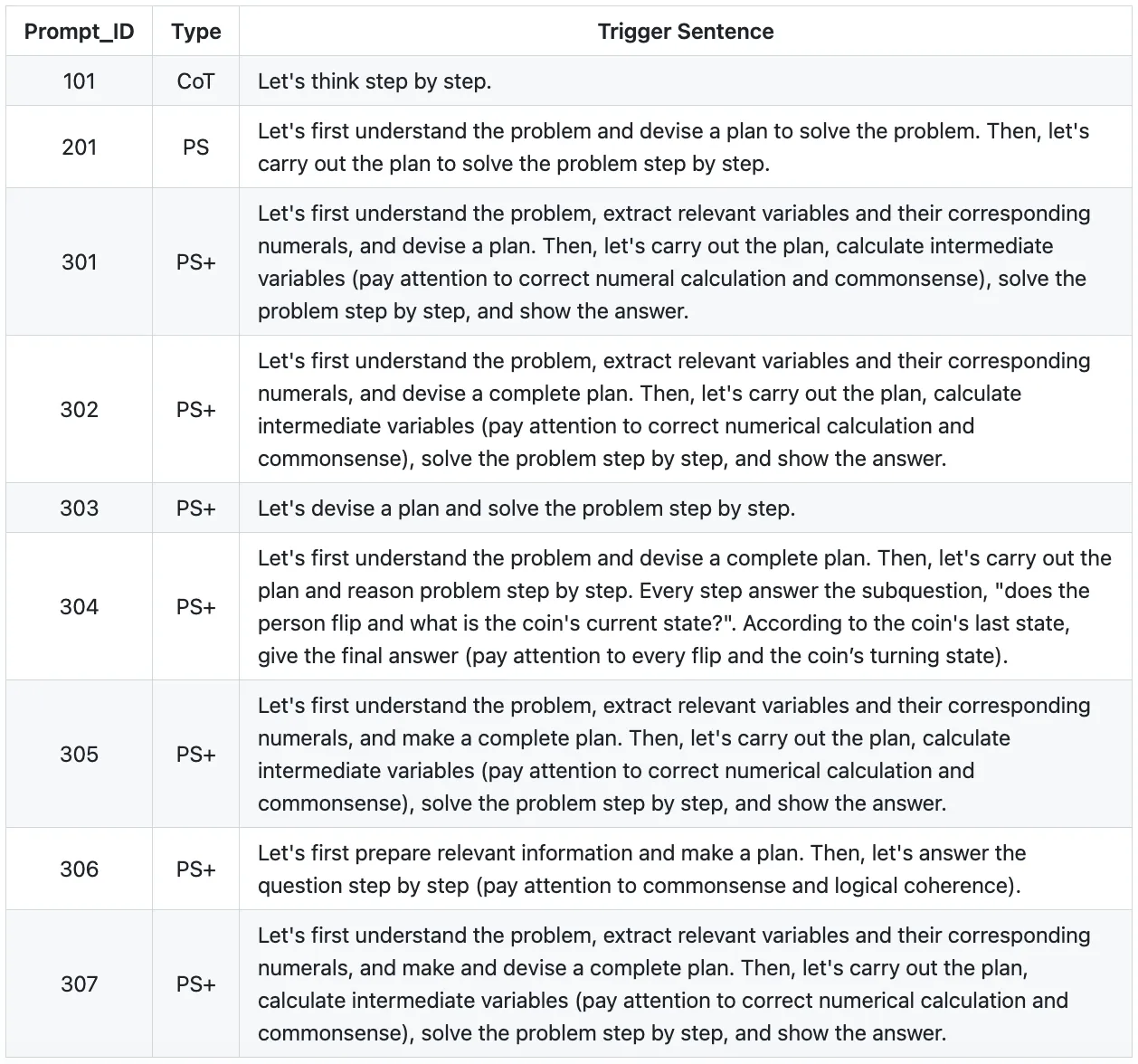
组织架构如下图示: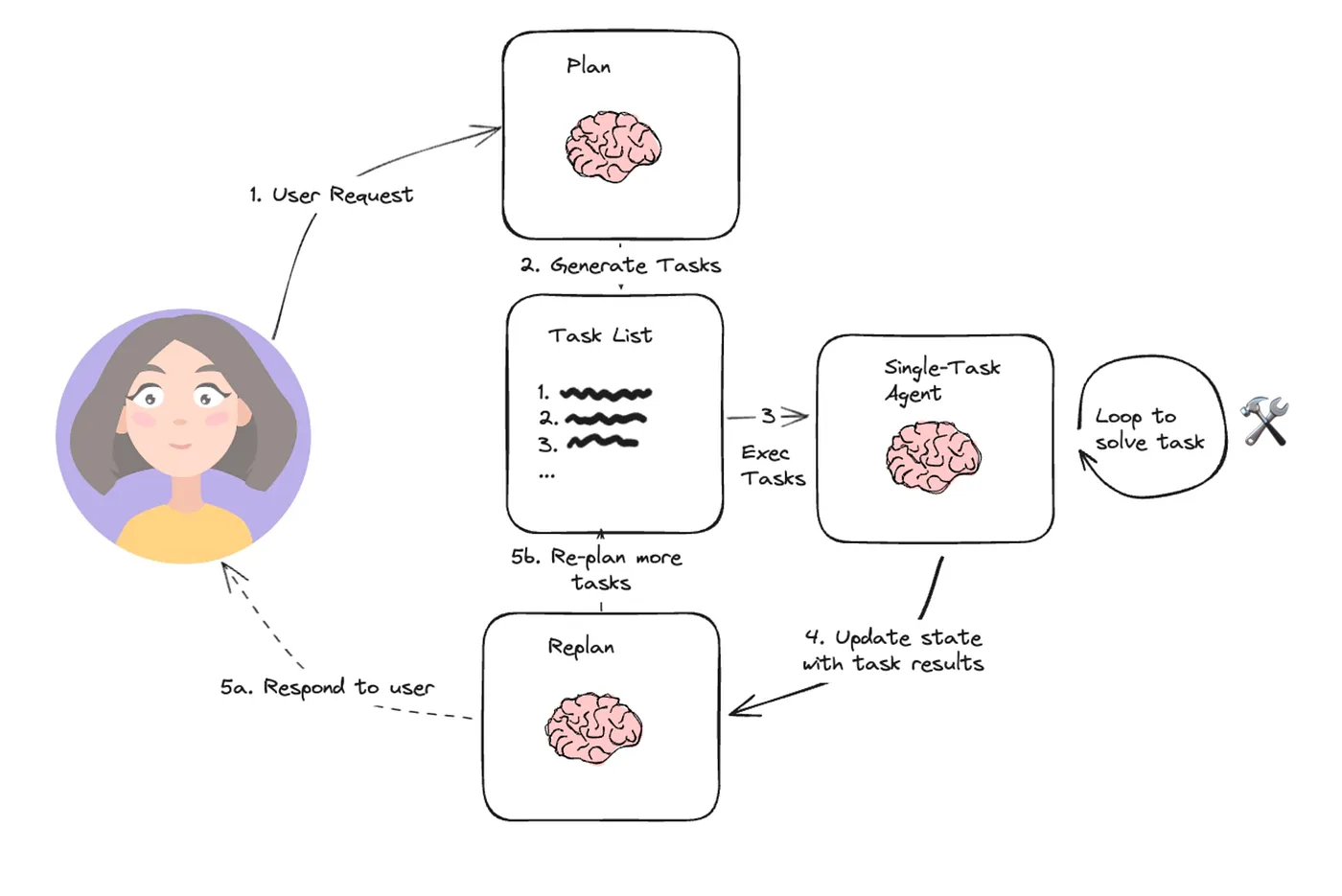
Planner
负责让 LLM 生成多步计划,以完成一个复杂任务。
在代码层面,又包括了一个 Planner 和 一个Replanner。Planner 负责生成初始计划,Replanner 负责在执行过程中,根据观察结果,根据当前的进度,调整计划。因此,Replanner 的提示词不仅仅包含零样本输入,还包括目标、原始计划以及已完成步骤的状态。
Executor
接收用户的查询和计划中的步骤,然后调用工具来完成任务。
其他工作流模式
这里,我们对上述列出的其他模式进行简要介绍。
1. Reason without Observation (REWOO)
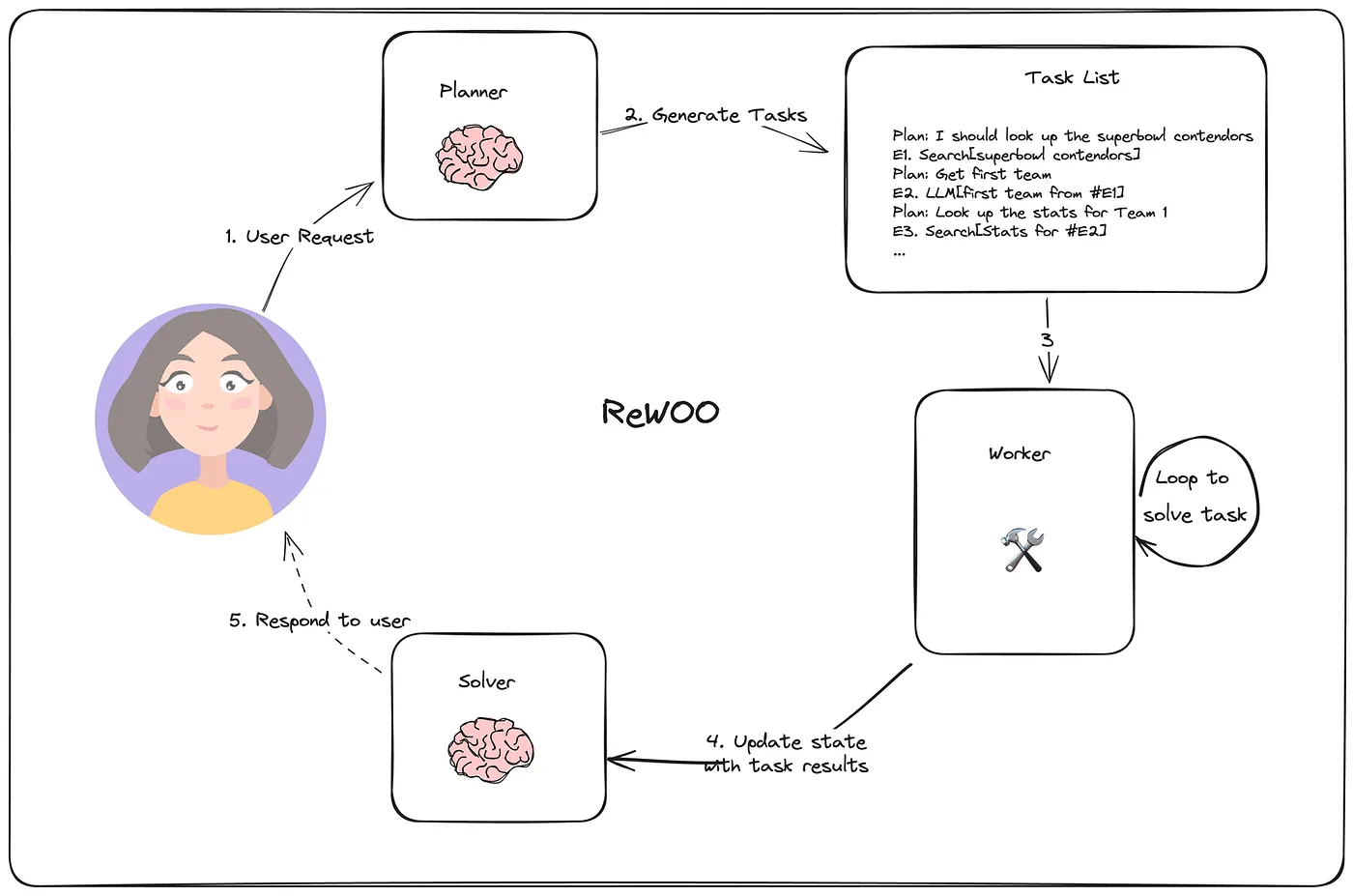
REWOO是 ReAct 中观察过程的变体。 ReAct 遵循的结构是:思想 → 行动 → 观察,而 REWOO 通过删除显式观察步骤来简化这一过程。相反,它隐式地将观察嵌入到下一个执行单元中。在实践中,下一个执行者会自动观察上一步的结果,从而简化流程。
2. LLMCompiler
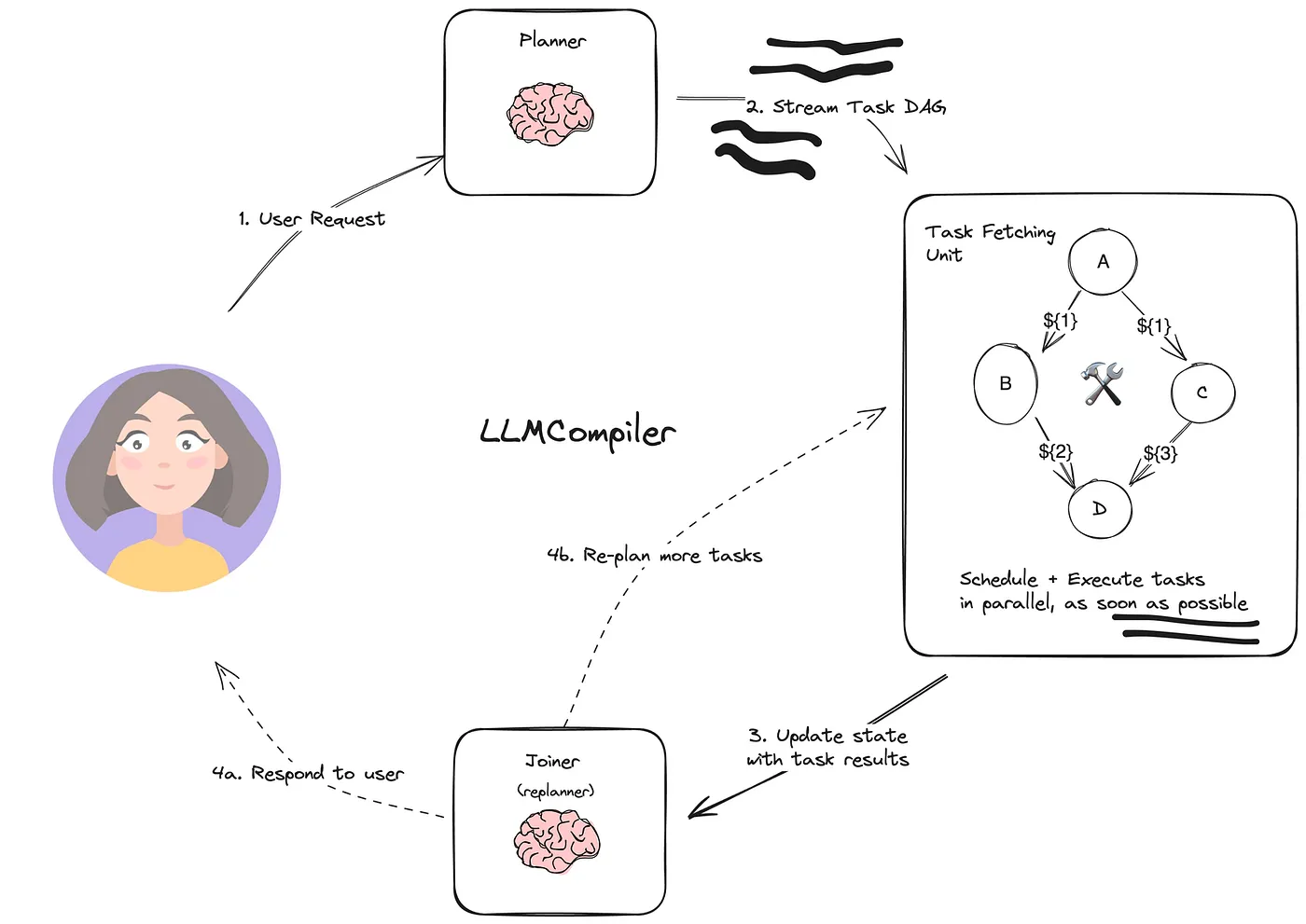
在计算机科学中,编译器指的是协调任务以优化计算效率的过程。原始论文中描述的 LLM 并行函数调用编译器背后的理念简单但有效:它通过启用并行函数调用来提高效率。例如,如果用户询问”AWS Glue 和 MWAA 有什么区别?”,编译器会同时搜索这两个 AWS 服务的定义并合并结果,而不是按顺序处理每个查询。
3. Basic Reflection
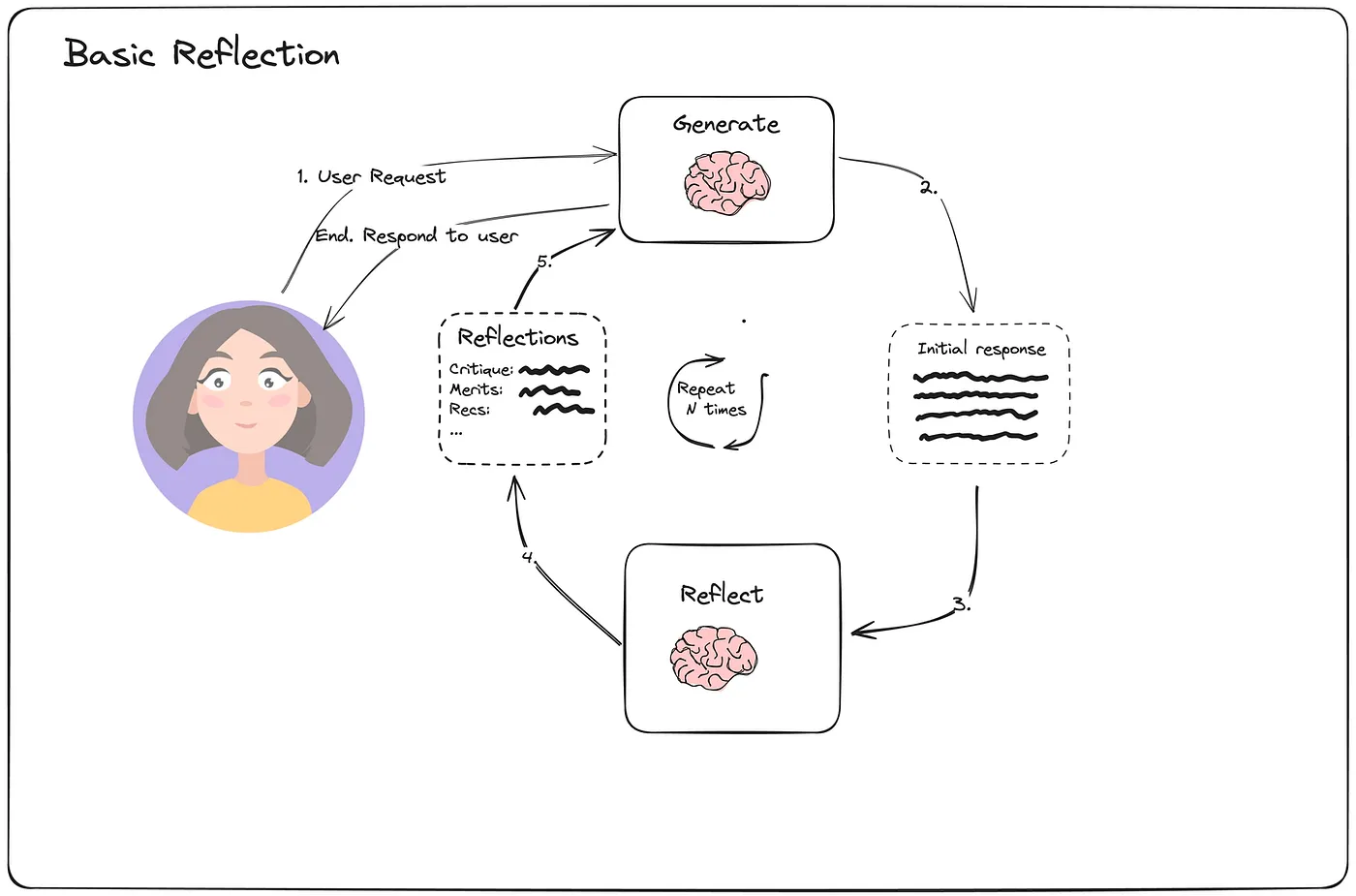
基本反思可以与学生(生成器)和教师(反射器)之间的反馈循环进行比较。学生完成作业,老师提供反馈,学生根据反馈修改作业,重复这个循环,直到任务圆满完成。
4. Reflexion
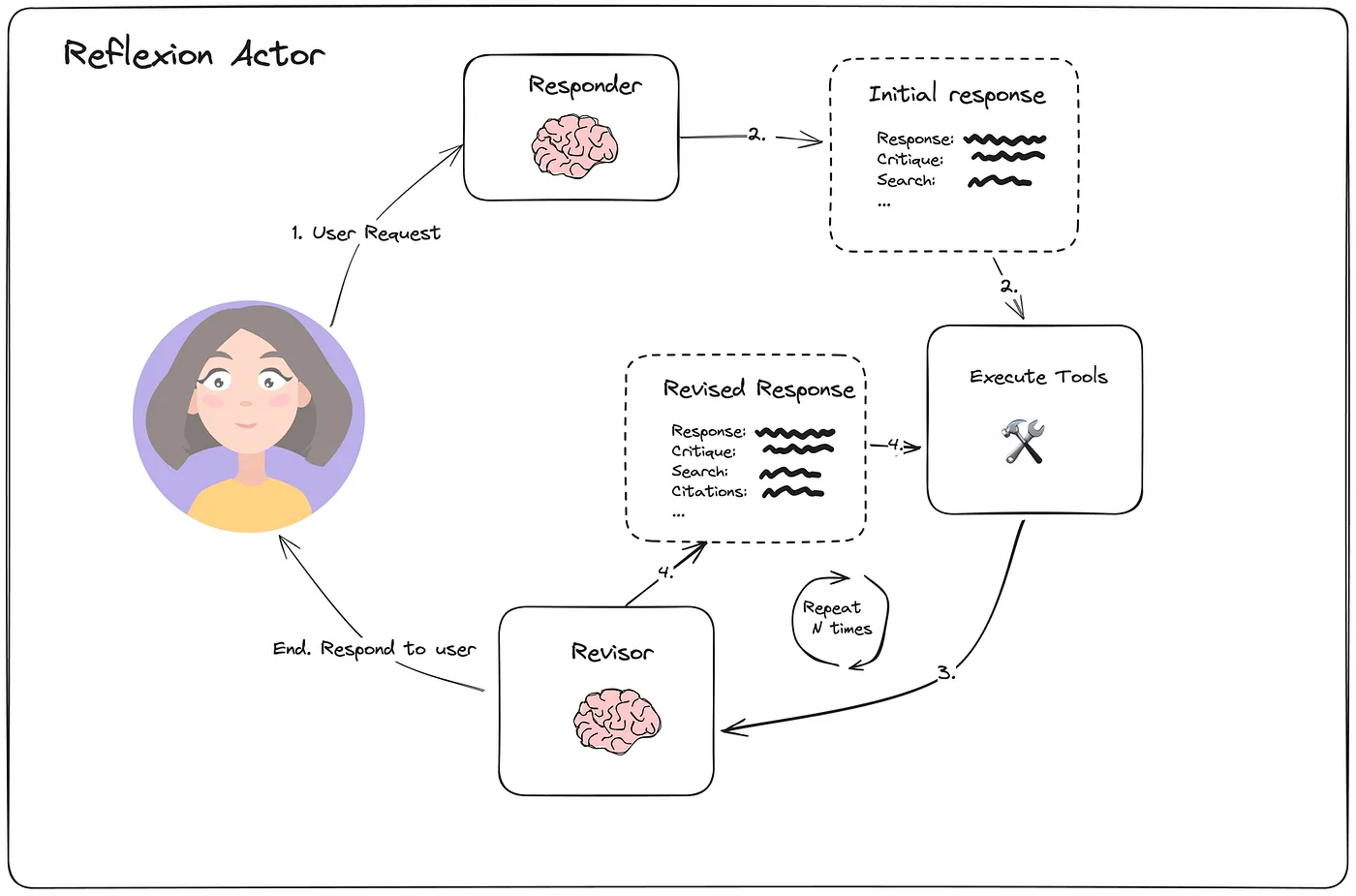
反思建立在基本反思的基础上,结合了强化学习的原则。在论文 Language Agents with Verbal Reinforcement Learning 中描述的这种方法超越了简单的反馈。它使用外部数据评估响应,并强制模型解决任何冗余或遗漏,使反思过程更加稳健,输出更加精致。
5. Language Agent Tree Search (LATS)
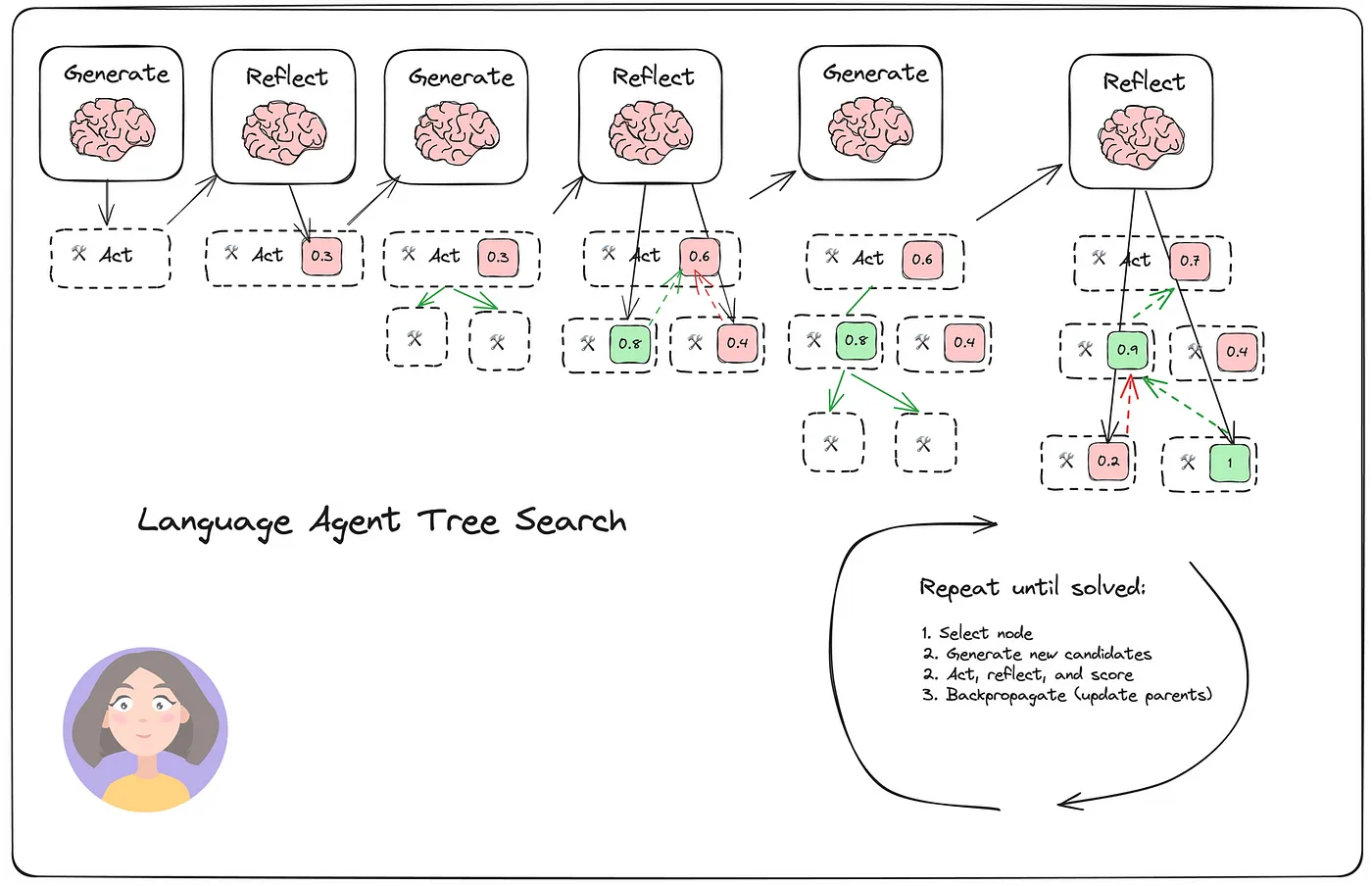
LATS 在论文 Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models进行了详细介绍。它结合了多种技术,包括树搜索、ReAct 以及 Plan & Solve。 LATS 使用树搜索来评估结果(借鉴强化学习),同时还集成反射以实现最佳结果。本质上,LATS可以用以下公式表示:LATS = Tree Search + ReAct + Plan & Solve + Reflection + Reinforcement Learning.
在提示词设计方面,LATS 与早期方法(例如 Reflection、Plan & Solve 和 ReAct)之间的差异很小。关键的补充是树搜索评估步骤以及任务上下文中评估结果的返回。从架构上来说,LATS 涉及多轮基本反射,多个生成器和反射器协同工作。