
词语的语义受其上下文影响。例如,”model”一词在”machine learning model”与”fashion model”中表达完全不同的概念。
这种影响因素的计算和捕捉,正是 transformer 模型中 self-attention 机制的核心功能之一。
什么是 self-attention
自注意机制,在于让序列中的每个元素都能“关注”到其他元素(包括自己),从而学习到元素之间的相互关系,更好的“理解”这个元素的真正含义。亦如上面的 “model”,到底是指“模型”还是“模特”。
self-attention 的计算过程
直观地看,当我们遇到”fashion model”这个短语时,”fashion”自然引导我们理解后面的”model”是指”模特”而非”模型”。这正是上下文词汇对目标词语含义的自然引导作用,也是注意力机制要模拟的语言理解过程。
对于计算机来说,这种“理解”需要通过量化和计算来实现。
在 transformer 模型中,是通过 Q(Query)、K(Key)、V(Value)矩阵来完成上下文感知的。
对于输入序列,模型通过三个不同的参数矩阵 W^Q、W^K、W^V 将其分别转换为查询(Query)、键(Key)和值(Value)三种不同的表示。
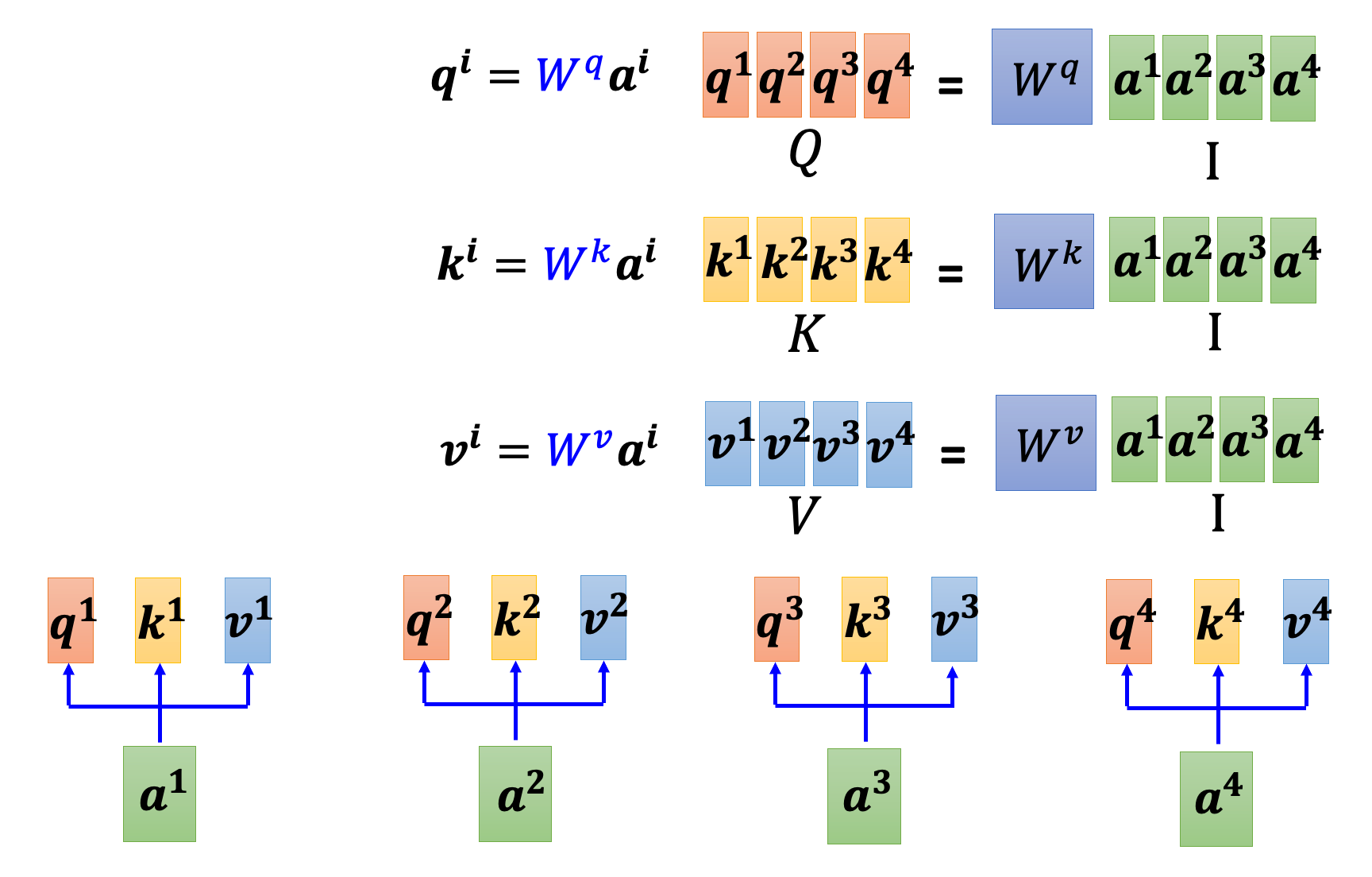
上图中,我们假设输入分别是 a1,a2,a3,a4。
其中,
- Q 是查询向量,用于与所有键向量进行比较。
- K 是键向量,用于与所有查询向量进行比较。
- V 是值向量,用于存储每个输入的值。
通过 Q 和 K 的点积来计算注意力权重 QK^T
最终,上面的注意力权重,就是上下文对当前元素的影响因子。
将注意力权重和 V 向量相乘,得到最终的输出。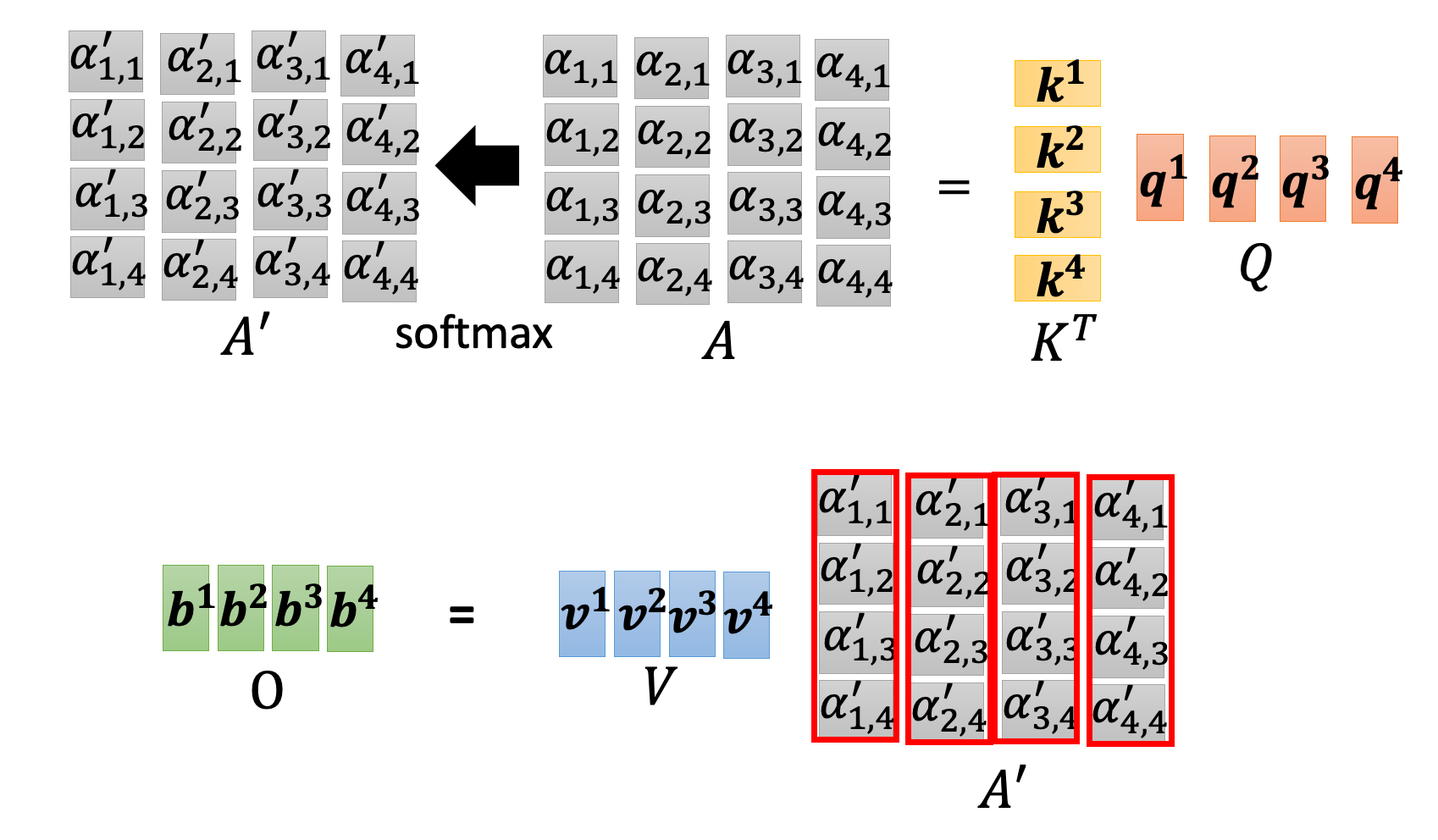
Multi-head attention
上面所展示的是单头注意力的计算过程。一个注意力头,通常用于捕捉序列中一个特定的特征。在实际过程中,通常使用多头注意力机制,来捕捉序列中多个不同的特征。
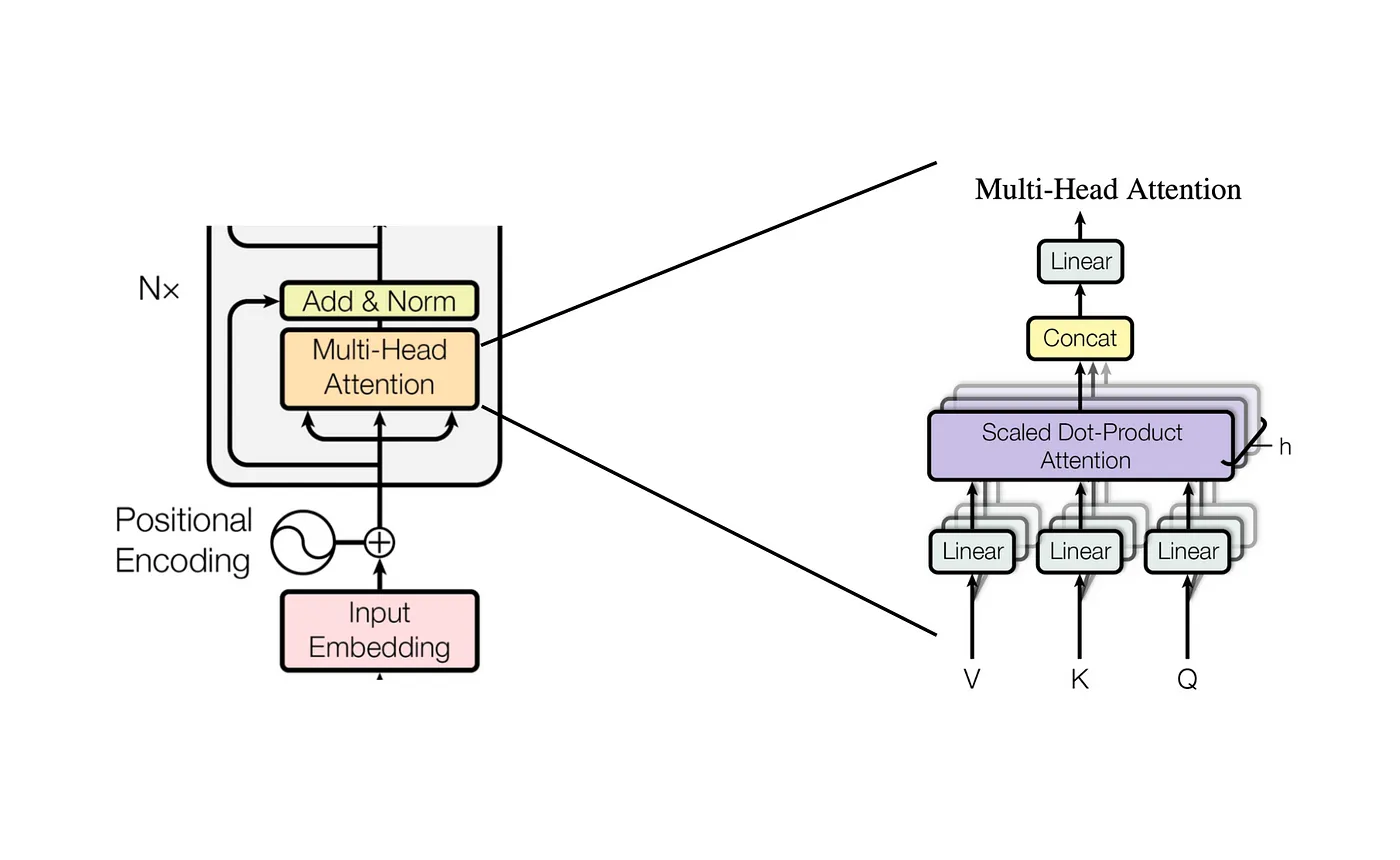
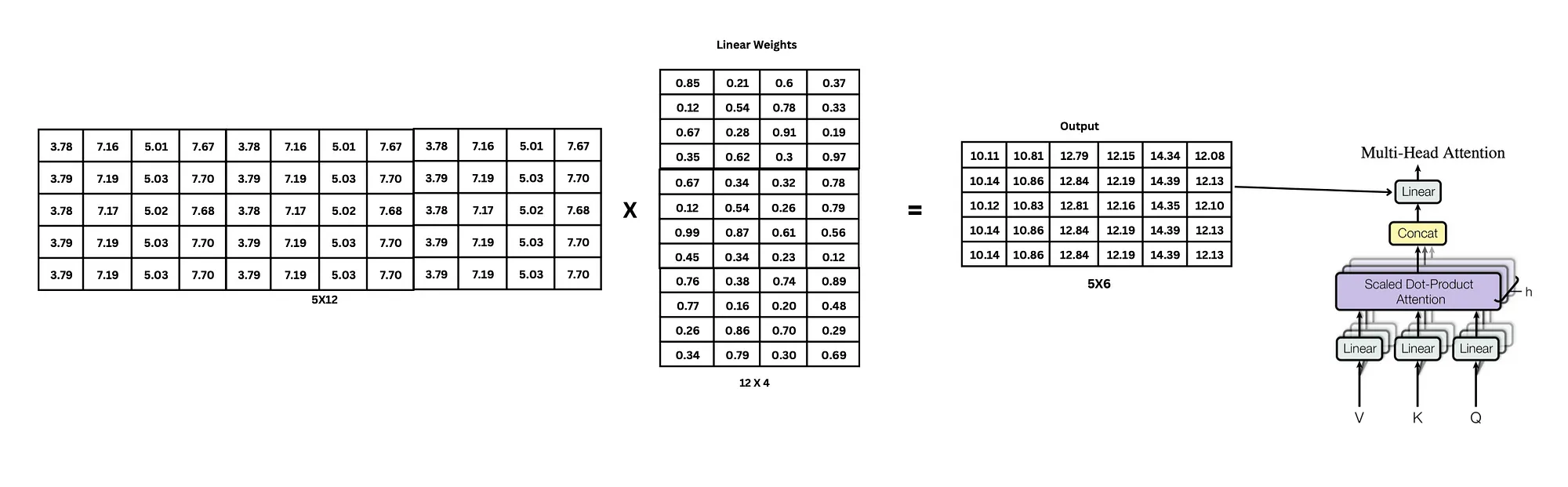
如上图示,亦如有 h 位专家(h个注意力头),每个专家从不同角度分析同一个问题:
- 每个专家(头)给出自己的分析结果(每个头的输出)
- 把所有专家的报告拼接在一起(Concat操作)
- 但这样拼接的报告可能过于冗长和不统一,所以你雇佣一个编辑(W^O矩阵)
- 编辑对拼接的报告进行整理和提炼(线性变换),生成最终的综合报告(多头注意力的输出)
参数矩阵是从哪里来的?
在上文中,我们注意到在很多变换的地方,出现多种不同的 W 参数矩阵。这种矩阵是哪里来的?
通常,这些矩阵是随机初始化的,就像一个没有任何经验的大脑。
随着模型不断训练,它会比较预测结果与真实结果之间的差距,通过反向传播算法调整这些参数矩阵中的值。这个过程就像人类通过不断实践和反馈来提升技能一样,参数矩阵逐渐学习到如何更好地处理语言信息,使模型的表现越来越接近人类的理解能力。
参考链接
Transformers (how LLMs work) explained visually | DL5
Understanding Transformer Architecture Using Simple Math