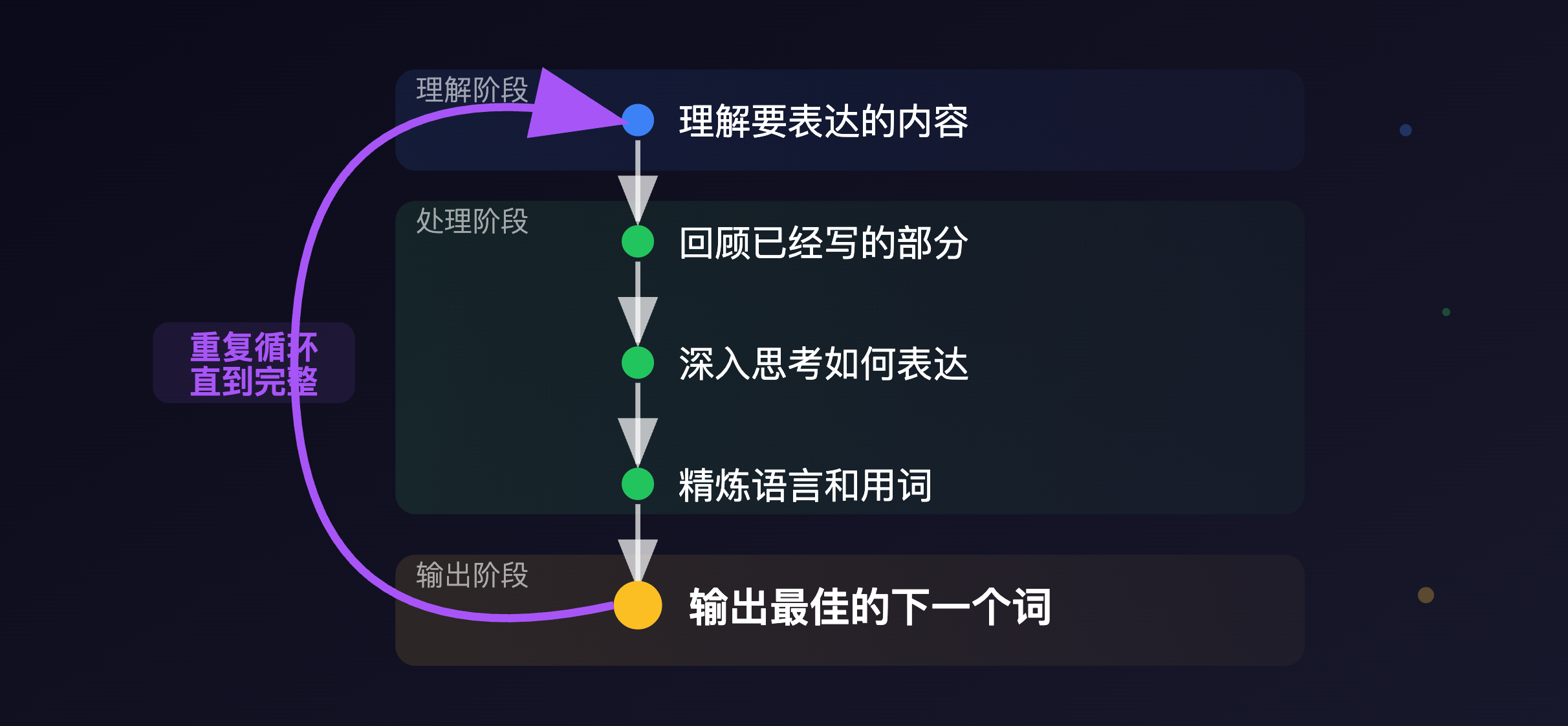
编码器是’理解者’,解码器是’表达者’。解码器不仅依赖编码器的输出,还因其自回归特性需要理解已生成内容,才能生成下一个token。
三角函数与位置编码:Transformer 模型的核心设计
多头注意力机制:Transformer 模型的核心设计(二)
前馈神经网络:Transformer 模型的核心设计(三)
在上面三篇文章中,我们详细介绍了编码器部分。接下来,我们做一下简要回顾,关注输入数据在编码器中被转化的主要过程:
- 数据先被向量化,然后被投入到了位置编码过程。位置编码使得每个 Token 自身具备了位置信息,这为后续并行计算奠定了基础。
- 位置编码的输出,被送入多头注意力机制。多头注意力机制,让每个 Token 融合了丰富的上下文信息。简单来说,每个携带了位置信息的 Token,被分解为了:
- Q 向量,查询向量。它代表了当前 Token 的信息需求。Token 本身具备有丰富的语义,比如说 “鸿蒙” 一词,它到底是代表一种操作系统,还是神话故事中的概念,这需要通过上下文来决定。
- K 向量,键向量。它代表了当前 Token 的信息特征。Q 和 K 的点积,可以得到注意力分数矩阵。对于矩阵中位置(i,j)上的元素,表示第 i 个 Token 对第 j 个 Token 的关注程度。
- V 向量,值向量。它代表了当前 Token 的信息载体。注意力权重矩阵与 V 的加权求和,可以得到融合了上下文信息的 Token 表示。
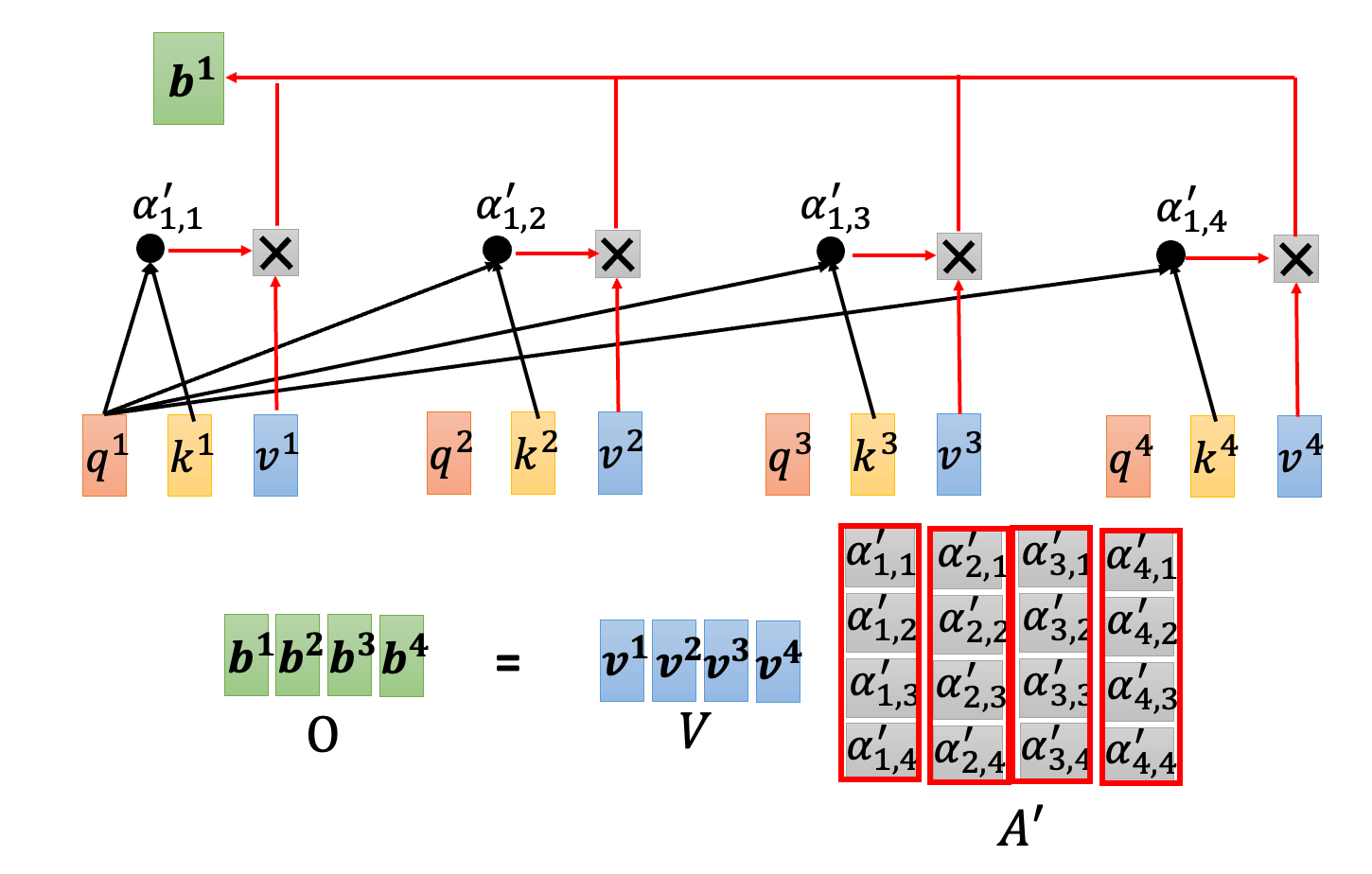
- 多头注意力机制的输出,被送入前馈神经网络。前馈神经网络的任务,是对融合后的信息,进行进一步的特征转换。转换的本质,是为了通过非线性拟合捕捉到数据中蕴含的复杂模式,并输出新的特征表示。比如,”今天天气很好” 被转为 [今日时间特征, 评价对象特征, 主语特征, 被修饰特征, …]
接下来,这些特征会进入到解码器中进行进一步处理,从而得到目标序列。
解码器部分,主要由掩码注意力机制、交叉注意力机制和前馈神经网络组成。
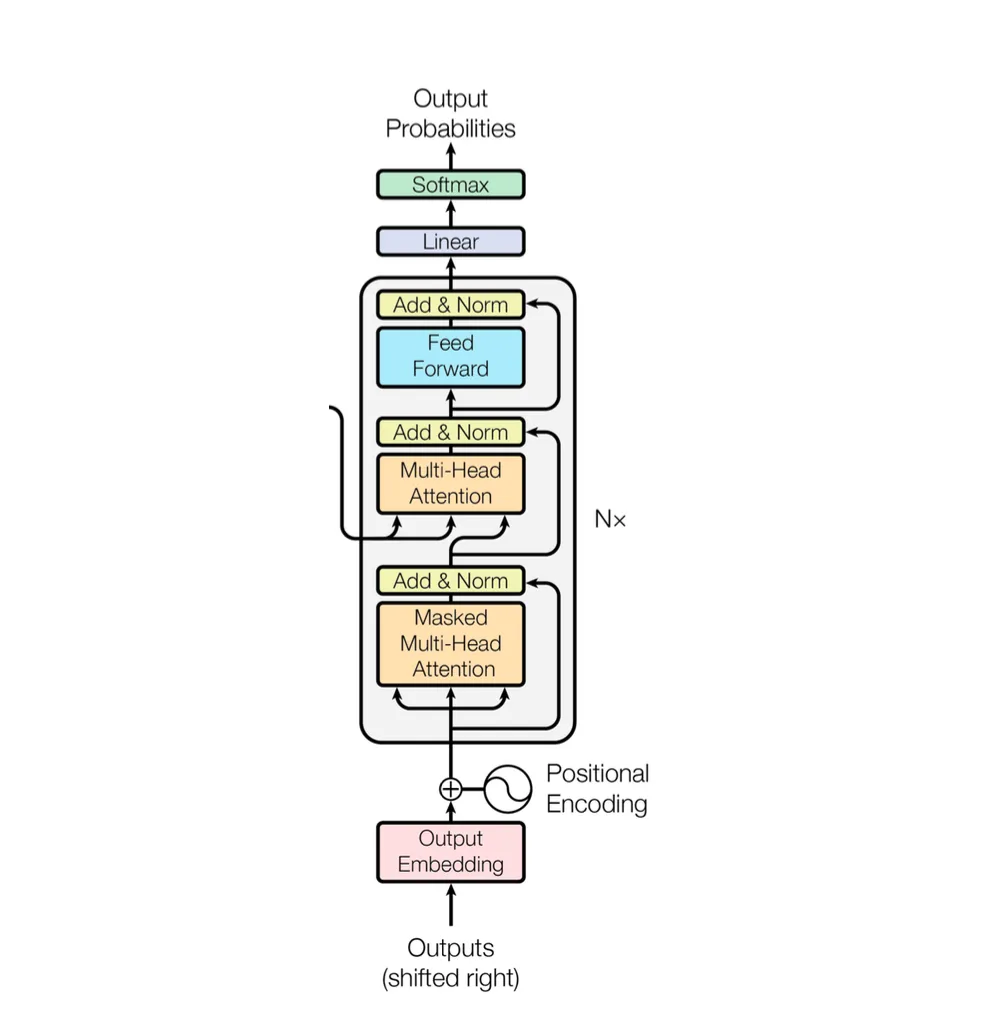
掩码注意力机制
掩码注意力机制和注意力机制类似,但是它加入了 “下三角矩阵” 作为掩码,控制信息流动,确保模型遵守任务的信息可见性约束。
在训练阶段,目标序列是一次性输入的,因此需要使用掩码注意力机制,确保模型只能看到”过去”,不能看到”未来”。
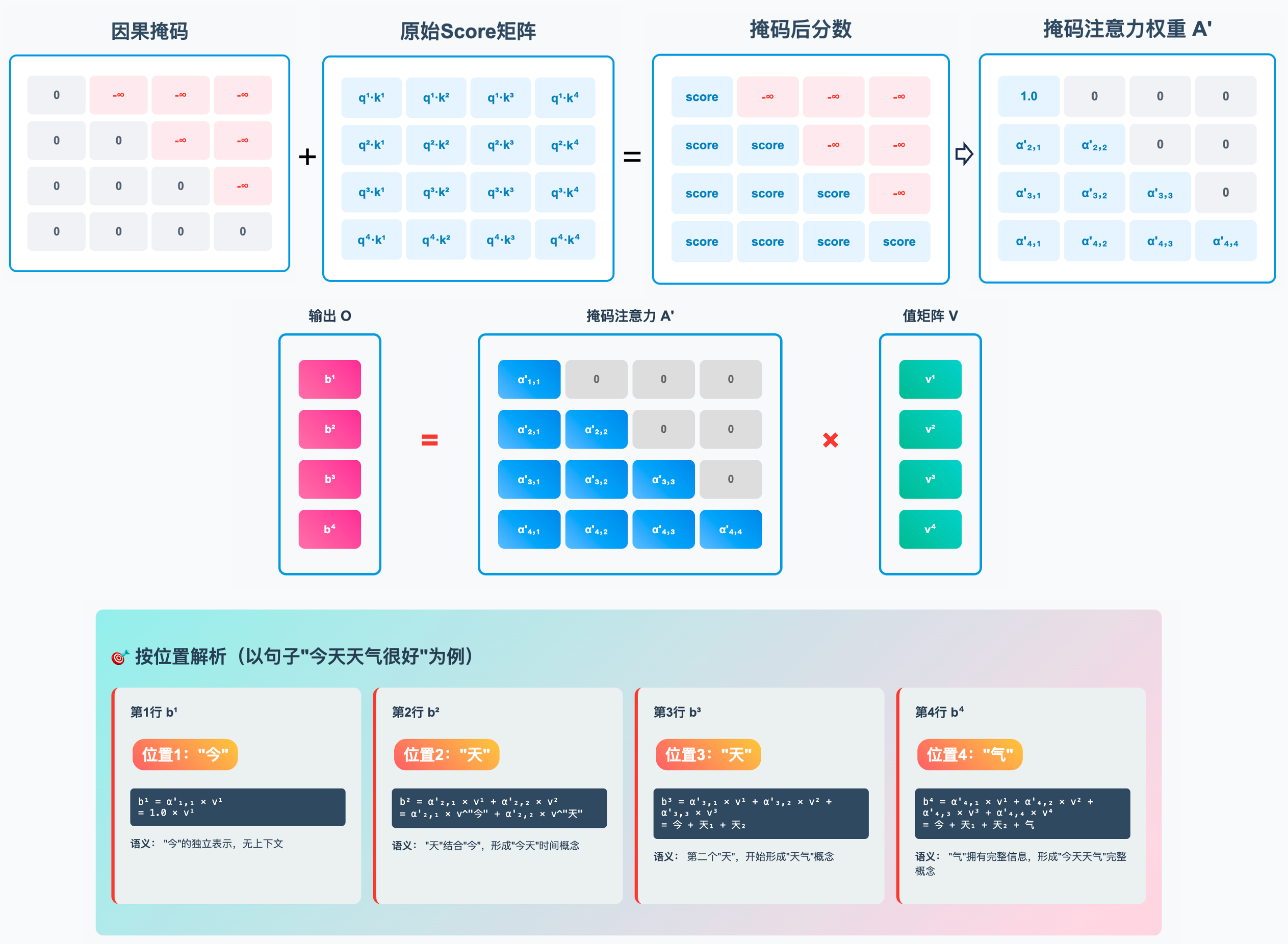
如上图所示,可以看到每个位置只能获取到自身及其之前位置的信息。例如,b4 只能看到 b1、b2、b3 和自身的信息。这就像是一个讨论会,每个人依次发言,后面的人会听取前面的发言,他们会结合前人的发言,以及自己的理解,来形成自己的发言。
预测阶段和训练阶段都采用掩码注意力机制,但实现方式有所不同:
- 在预测阶段,模型自回归地生成序列,即利用已生成的token(如b1、b2、b3、b4)来预测下一个token(如b5)。
而在训练阶段,通过教师强制(teacher forcing)策略,模型使用真实目标序列作为输入,同时每个位置的预测输出都会参与损失函数的计算,从而优化整个模型。
交叉注意力机制
交叉注意力让模型具备跨序列(源序列和目标序列)融合信息的能力。
自注意机制解决的问题是”在当前序列中,每个位置应该如何与其他位置建立关联?”,而交叉注意力机制解决的问题是”在生成目标序列的每个位置时,应该从源序列中提取哪些相关信息?”。
1 | 输入 → 掩码自注意力 → 残差+归一化 → 线性变换 → 注意力计算 → 信息融合 → 输出 |
用掩码自注意力输出经过残差连接、层归一化处理后,通过线性变换得到的查询矩阵Q,去查询编码器输出的键矩阵K,计算Q·K^T后经过缩放(÷√d_k)和SoftMax归一化,得到注意力权重矩阵。然后用注意力权重矩阵对编码器输出的值矩阵V进行加权求和,最终得到融合了源序列信息的Token表示。
前馈神经网络
经过掩码自注意力机制和编码器-解码器交叉注意力机制协同工作,使Token表示既包含目标序列的上下文信息,又融合了源序列(编码器)的相关信息。
这些经过注意力处理的 Token 表示,通过残差连接和层归一化后,被送入前馈神经网络。前馈网络通过两层线性变换和激活函数,对特征进行非线性变换和抽象,提取更深层的语义特征。
前馈网络的输出同样经过残差连接和层归一化处理,得到最终的 Token 特征表示。
随后,这些特征通过线性投影层映射到词汇表维度空间,再经过Softmax函数转换为概率分布。
在推理阶段,根据这个概率分布,通过解码策略(如贪心搜索:总是选择概率最高的token)确定下一个生成的Token。而在训练阶段,则使用教师强制策略,直接使用真实标签作为下一步的输入。
最后,以翻译为例,让我们看一个完整的 Transformer 数据处理流程:
参考链接
Understanding Transformer Architecture Using Simple Math
But what is a neural network? | Deep learning chapter 1
【機器學習2021】自注意力機制 (Self-attention) (上)