
让计算机理解非结构化数据,就像发现了一座蒙尘已久的矿山。
本节,我们通过 Milvus 来认识一种解决该问题的方式。
一、基本概念
非结构化数据
图片、音频、视频以及自然语言,这些信息无法遵从一个预定义的模型、方式或者组织。这些数据,可以通过 AI 或者 ML 模型转换成嵌入式向量。转换的目的,主要是为了能够实现近似搜索。
嵌入式向量
嵌入(”嵌入”(Embedding)通常指的是将高维数据映射到低维空间的过程,将原始数据表示为连续的向量或特征表示形式。)式向量,可以作为非结构化数据的特征抽象。从数学上将,一个嵌入式向量是一个数组(浮点数或者整数)。
向量近似搜索
向量近似搜索,就是在数据库中找到一个和目标向量最为相似的向量的搜索、查询过程。最近邻搜索算法(ANN,Approximate nearest neighbor) 是常用的加速搜索过程的算法。
如果两个嵌入式向量非常接近,这意味着它们的原始数据也在某个语义上也非常接近。
二、Milvus 是什么
Milvus 作为一个数据库,其设计的目的,是为了能够处理基于向量的查询。不像传统的关系型数据库,关系型数据库主要处理根据定义好的模式构成的结构化数据,Milvus 能够将非结构化数据转换为嵌入式向量。
为了使计算机能够理解并处理非结构化数据,通过嵌入式技术,它们被转换为了向量。Milvus 可以存储并索引这些向量,分析它们的相关关系。
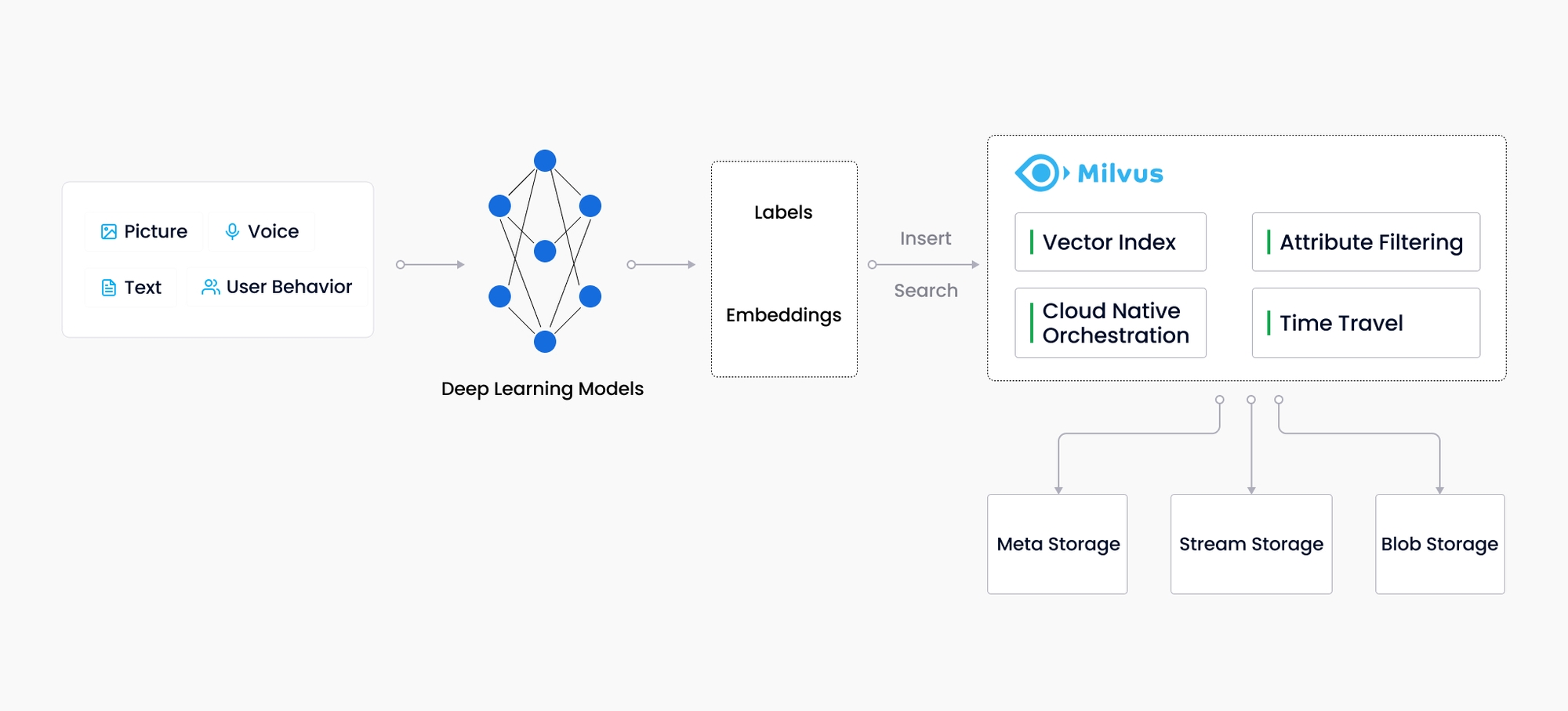
三、Milvus 设计
作为一个既可以云部署也可以本地部署的数据库,Milvus 从设计上分离了存储和计算部分。为了增强弹性和灵活性,Milvus 中所有的组件都是无状态的。
系统被分解成四个层次:
- 访问层:访问层是由一组无状态的代理组成,扮演着系统的前端层,对用户来说,它就是一个 endpoint。
- 调度服务:调度服务将任务分配给工作节点,扮演着整个系统的大脑。
- 工作节点:工作节点扮演着系统的胳膊和腿的角色。它是一个执行者,遵从来自调度服务的指令,或者一些由用户触发的 DDL/DML 指令。
- 存储:存储是系统的骨骼,它负责数据的持久化。
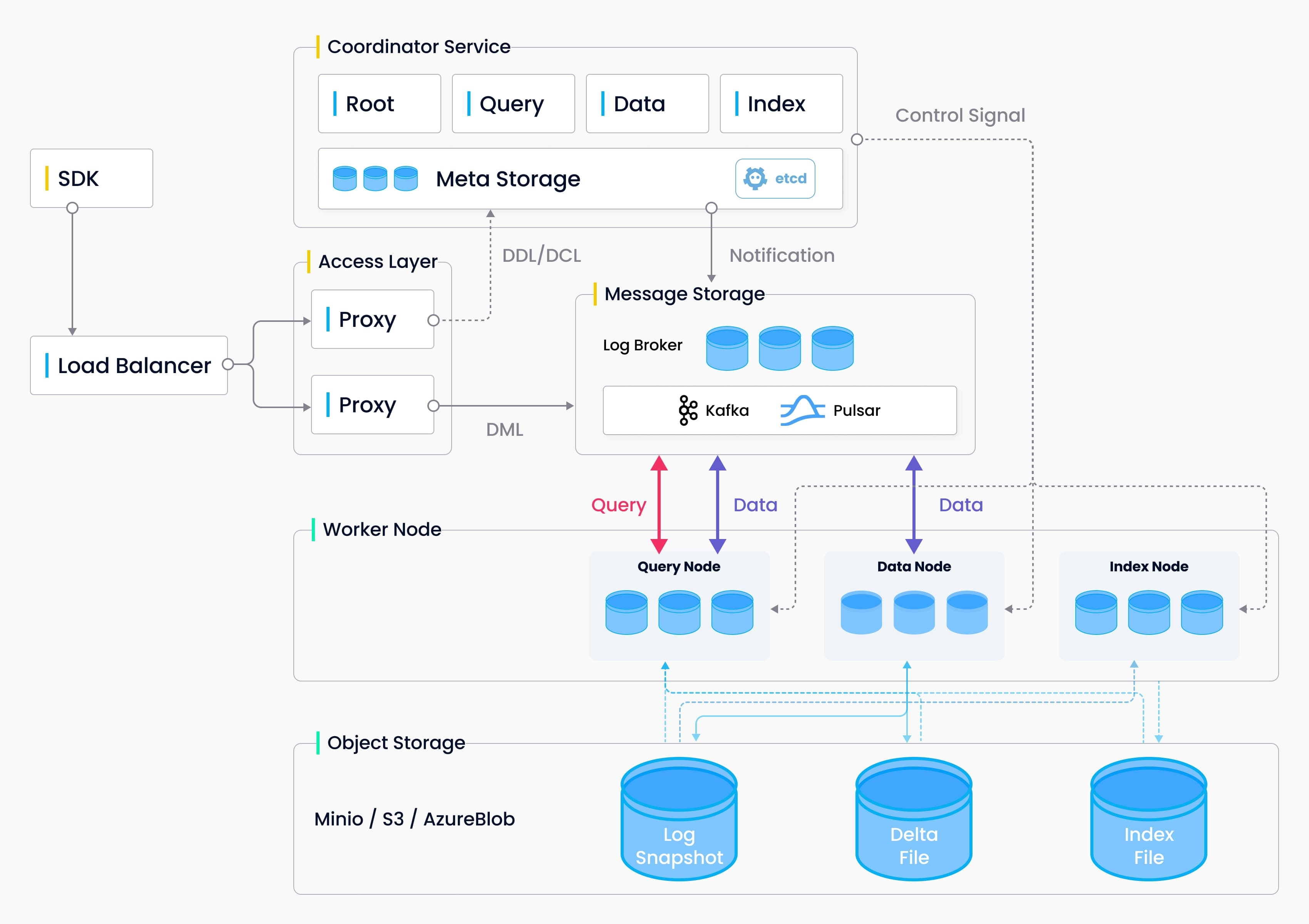
四、Milvus 所支持的索引和度量标准
索引,是数据的组织单位,在使用搜索和查询已插入的数据之前,我们必须声明好数据的索引类型和相似性度量标准。如果你不指定,Milvus 默认将执行暴力搜索。
索引类型
Milvus 所支持的大部分向量索引类型,都支持最近邻搜索,包括:
- FLAT:FLAT 适用于小规模、百万数据集上的精准搜索。
- IVF_FLAT:一种基于量化的索引。最适合在精准性和查询速度之间寻求理想平衡的情况。还有一个 GPU 版本的 GPU_IVF_FLAT。
IVF(Inverted File) 倒排文件。
“倒排”的含义是将文档与关键词之间的映射关系反转,从文档-关键词的映射建立成了关键词-文档的映射。这个反转的过程使得文档的检索更高效,因为可以根据关键词快速查找相关的文档。倒排文件是信息检索领域的核心概念,用于支持文本搜索引擎和其他信息检索任务。
在 Milvus 的上下文中,IVF_FLAT 是一种基于倒排文件的索引结构,用于高维向量数据的存储和检索。这种索引结构的基本思想是将向量数据分成不同的组(或桶),每个组中包含了一组相似的向量。这些组的信息被存储在倒排文件中,以便在查询时可以快速定位到相似的向量组,从而提高搜索效率。
具体来说,倒排文件的建立过程如下:
- 文档处理:文档被分解成词汇项(terms)或关键词,通常是文档中的单词或短语。
- 建立索引:对于每个关键词,建立一个倒排列表(Inverted List)。这个列表包含了包含该关键词的文档的标识符或位置信息。每个文档的标识符或位置信息都与关键词建立了映射。
- 查询处理:当进行搜索时,用户提供一个或多个关键词。系统会查找这些关键词对应的倒排列表,然后合并这些列表,找到包含所有查询关键词的文档。这些文档被认为是与查询相关的文档。
- IVF_SQ8:一种基于量化的索引。最适合在磁盘、CPU、GPU、内存消耗非常有限的使用场景。
- IVF_PQ:一种基于量化的索引。适合追求高查询速度的使用场景,即使会牺牲准确性。还有一个 GPU 版本 GPU_IVF_PQ。
- HNSW:基于图的索引,最适合对搜索效率有高要求的情况。相较于基于向量的索引,它需要更多的存储空间和计算资源。
基于量化的索引:一种用于高效存储和搜索高维向量数据的索引方法。其目标是在大规模高维向量数据集合中找到与查询向量最相似的数据点。 基于量化的索引的核心思想,是将高维向量映射到一个低维的向量空间,以减少存储和搜索的复杂性。具体来说,这个过程通常包括以下步骤:
- 量化:原始高维向量被映射到一个低维向量,通常通过一种量化方法实现。
想象一下,高维向量就像是一个包含很多数字的长串,每个数字都代表了向量的一个特征或属性。这个长串可能非常长,因为它包含了很多特征,所以处理它可能会很复杂。
现在,如果我们想要简化这个长串,使它更容易处理,就像把一本厚厚的书缩减成一个小册子一样。这个缩减的过程就是”量化”。在量化中,我们会使用一种方法,将原来的数字变成更简单的数字,通常是整数。这些新的数字组成了一个新的、更短的串,代表了原始向量的一个简化版本。
这种简化的向量就像一个摘要或代表,它保留了一些原始向量的特性,但变得更加紧凑和易于管理。然后,我们可以使用这个简化的向量进行快速搜索和比较,而不需要处理原始的复杂高维向量。这有助于节省存储空间和提高搜索效率。
总的来说,量化是将复杂的高维向量变成简化的低维向量的过程,使得数据更容易处理和存储,同时保留了一些重要的信息,以便进行相似性搜索等任务。- 索引构建:将量化后的向量以某种结构存储在索引中。这个结构可以是树状结构、哈希表等。
- 查询处理:在进行查询时,将查询向量进行同样的量化,然后使用索引中的结构和快速定位近似匹配的数据点。通常,这个过程会跳过那些与查询向量差异较大的数据点,从而提高搜索效率。
相似性度量
在 Milvus 中,相似性度量被用于在向量中,进行相似性度量。选择一个好的距离度量,可以显著提升分类和聚类的性能。根据输入数据的形式,选择特定的相似度度量方式以获得最佳性能。
欧几里得距离

余弦距离

海明距离(Hamming)
两个等长字符串s1与s2的汉明距离为:将其中一个变为另外一个所需要作的最小字符替换次数。例如:
The Hamming distance between “1011101” and “1001001” is 2.杰卡德(Jaccard)

五、Milvus 常用术语

Storage
存储包括了:元数据存储(Meta Storage),日志代理(Log Broker),对象存储(Object Storage)。
元数据存储(Meta Storage)
这部分存储区域,存储了诸如节点状态、集合模式(Collection Schema)
Milvus 是一个开源的用于管理向量数据的开源数据库,高效的向量索引和快速的相似度查询是它主要的特点。
集合(Collection)
集合,就像传统数据库中 Table 的概念,用于存储和管理向量数据。向量管理,是它和传统数据库最主要的区别。
Collection 创建:
1 | from pymilvus import Collection |
- name: 集合的名字;
- schema:集合的模式,或者说集合结构的定义。
- using:通过指定服务器的 alias,确定希望在哪个服务器上创建这个 Collection。可选参数。
- shards_num:为 Collection 创建的分片的个数。可选参数。
https://milvus.io/docs/glossary.md#Sharding
分区(Partition)
Collection 数据可以分割存储到多个 Partition 中。每个 Partition 中包含有多个 Segments.
Partition 实际是一个逻辑上的概念,包括下面提到的 Segment 和 Shard,都是为了分割、存储 Collection 中的数据,实现数据的快速访问。
片段(Segment)
Segment 是由 Milvus 创建的持有插入数据的数据文件。
一个 Collection 可以拥有多个 Segments,一个 Segment 可以包含多个 Entities。
在进行向量相似度搜索时,Milvus 将扫描每个 Segment 并返回搜索结果。
Segment 通常会有两个状态:增长状态和密封状态。增长状态下,仍然接收新插入的数据,直到其到达密封状态;密封状态下,不再接收新数据,而且这些数据将被写入到对象存储(object storage)中。从增长状态到密封状态,是由于存储的实体(entities)的数量达到了预设的阈值,或者,处于增长状态的时间超出了指定的跨度。
关于 Partition 是一种逻辑上的分区;Segment 是一种物理上的分割。因此,一个 Partition 可以包含若干个 Segment。
分片(Shard)
分区是为了 读取优化,而分片主要是为了 写入优化。写入操作可以被分发到不同的节点上,实现并行化。默认情况下,单个 Collection 会包含两个 Shards。目前,分片的方法是基于主键(primary key)的哈希。
以下答案来自 ChatGPT:
在 Milvus 中,一个集合可以被划分为若干个 Shard,每个 Shard 由多个 Segment 组成,而 Partition 则是对每个 Shard 内部的数据进行逻辑上的分组。下面是它们之间的具体区别:
- Shard:是 Milvus 分布式部署模式下的最小存储单元,每个 Shard 对应一个节点,并包含一个或多个 Segment。Shard 旨在通过数据分片技术来实现分布式存储和查询,从而提高系统的横向扩展和负载均衡性能。
- Segment:是 Milvus 的单机部署模式下的最小存储单元,每个 Segment 包含一部分向量数据及其索引结构和元数据信息。Segment 旨在为向量存储和查询提供高效性能。
- Partition:是对每个 Shard 内部的数据进行逻辑上分组的操作,用于方便地对数据进行管理和查询。每个 Partition 可以包含一个或多个 Shard,不同 Partition 之间的数据是相互独立的。
总体来说,Shard、Segment 和 Partition 是 Milvus 数据管理的三个最重要的概念。其中 Shard 和 Segment 用于实现数据的存储、索引和查询,Partition 则用于对数据进行逻辑上的分组,方便用户进行数据管理和查询。同时,Shard 可以和 Segment 联合使用,Partition 则将 Shard 进一步划分为用户自定义的逻辑数据单元。
模式(Schema)
Schema 是定义数据类型和数据属性的元信息(meta information),这些元信息包括了数据类型(int、double、vector 等)和数据属性(是否是主键、是否自增等)的定义。
每个 Collection 都有它的 Schema,包含了所有字段级别的 Schema(field schema)、Collection 描述等。字段级别的 Schema 又包含了字段类型以及其它字段属性。
1 | fields = [ |
如上,字段类型可以分为标量和向量。其中,标量包括:DataType.INT8、DataType.INT16、DataType.INT32、DataType.INT64、DataType.BOOL、DataType.FLOAT、DataType.DOUBLE、DataType.VARCHAR等;向量包括:DataType.FLOAT_VECTOR、DataType.BINARY_VECTOR。dim 表示向量的维度。
字段(Field)
字段,是组成一个实体的一个单元。一个字段可以是结构化数据或者向量。
实体(Entity)
一个实体表示现实世界中的一个对象,包含了一组字段。
1 | import random |
嵌入式向量(Embedding Vector)
嵌入式向量是非结构化数据 特征 的抽象。这些非结构化数据包括:邮件、传感器数据、照片等。从数学上讲,嵌入式向量就是一个 浮点类型或者二进制类型数据的数组。现在的嵌入式技术可以将非结构化数据转换为嵌入式向量。
向量索引
向量索引是从原始数据(raw data)中派生出来的,一般通过 降维打击 ,加速向量相似性搜索过程。
Milvus 同时支持基于内存的向量索引和基于磁盘的向量索引。
参考链接
https://developer.aliyun.com/article/1151228
https://yaoyichi.github.io/spatial-ai/w4w5.2-ch07-clustering.pdf
https://milvus.io/docs/overview.md#Example-applications